Filtered Subscriptions: Fine-Grained Cloud-Native Data Sharing



TLDR
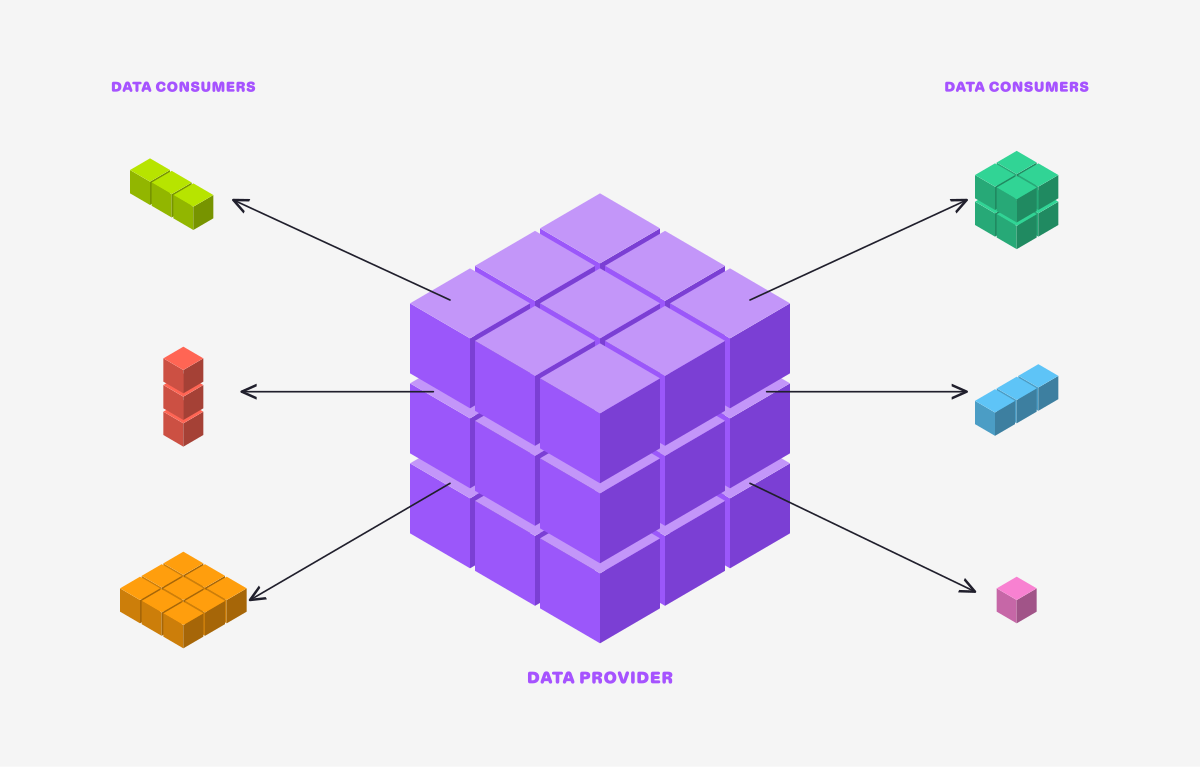
Earthmover’s filtered subscriptions allow data providers to create secure, read-only views into multidimensional data cubes, enabling more granular cloud-native data exchange between provider and consumer.
The Status Quo: Difficult Tradeoffs
Today, data providers face some difficult tradeoffs when deciding how to disseminate large geospatial datasets.
- Option 1 - Cloud Native - Embrace multi-file cloud-native formats like Geoparquet / Apache Iceberg (for vector data) or Zarr / Icechunk (for raster data); and provide direct access to analysis-ready datasets in cloud object storage. This provides excellent performance and convenience for the user, but is generally an “all or nothing” approach. Either you have access to the full dataset or not.
- Option 2 - API Gateway - The provider hides their data behind an API gateway, which provides fine-grained access controls and detailed metrics. This approach is more versatile for the provider, supporting complex pricing and permissioning schemes, but operating an API gateway at scale can become a major engineering challenge for the provider. And it’s generally less friendly to the user, who has to learn to talk to a new API. It can also be a severe performance bottleneck; most APIs can’t deliver data anywhere close to the throughput of S3 itself, meaning that the customer has to re-ingest the data to their own database before it can be used for serious analytics and AI.
- Option 3 - Bespoke Delivery - Deliver a custom dataset for each customer, pushing data to the customer’s storage in their format of choice. This is the ultimate convenience for the user. And a major pain for the provider. We once met a B2B weather sales team who was delivering the same weather forecast data in 10 different ways for 10 different customers. Unsurprisingly, that business unit was failing due to poor unit economics.
Option 1 is working great for the open-data community; it’s what you find in programs such as the AWS Open Data Registry and Source Cooperative and a large number of enthusiastic blogs. However, the commercial data market is still largely using Options 2 and 3, due to the need for more fine-grained control over which data are shared with the customer. Providers typically price data based on:
- the number of variables / parameters provided
- the spatiotemporal extent of the data
- the freshness / latency of the data
In an ideal world, a provider would produce their own master reference copy of their data once, in a cloud-native format in their own storage. (Picture a big multi-dimensional data cube with many variables.) And they could provide different customers with read-only views into different subsets of that data, without exposing the whole thing to everyone. This would be much more efficient for data provider and data user alike.
But this has not been technically possible…until now.

Necessary Ingredients: Icechunk and Virtual Chunks
Zarr provides an on-disk format for hierarchies of chunked, compressed arrays and is the core data structure in the Earthmover platform. Provider data consists of a few large Zarr data cubes with many dimensions, such as this ensemble forecast from Spire.
Zarr’s key names are deterministic, as in this hypothetical Zarr store:
s3://my-bucket/ocean-data.zarr/zarr.json
s3://my-bucket/ocean-data.zarr/temperature/zarr.json
s3://my-bucket/ocean-data.zarr/temperature/c/0/0/0
s3://my-bucket/ocean-data.zarr/temperature/c/0/0/1
...
s3://my-bucket/ocean-data.zarr/humidity/zarr.json
s3://my-bucket/ocean-data.zarr/humidity/c/0/0/0
s3://my-bucket/ocean-data.zarr/humidity/c/0/0/1
...(The keys with /c/ in them are chunks: blocks of compressed binary data organized in a rectangular grid.)
Even without the ability to list a bucket, if you know any one of these keys, you can easily guess others. Attempting to use AWS IAM roles to provide fine-grained access to different pieces of this dataset would be a sisyphean nightmare. And even if you could do it, the user’s software would break in unpredictable ways when attempting to access forbidden keys.
More advanced cloud-native data formats, such as Apache Iceberg and Icechunk, do two important things differently.
- Use unique random identifiers for most key names
- Don’t rely on listing the object store; instead employ “manifests” as part of the format
An Icechunk store might look like this on disk
s3://my-bucket/my-repo/snapshots/1CECHNKREP0F1RSTCMT0
s3://my-bucket/my-repo/snapshots/C7WT6HB19TD3DJQVZA50
s3://my-bucket/my-repo/snapshots/S83AZHK7D94DDPGYK4C0
...
s3://my-bucket/my-repo/manifests/5WER3V5TSWDBMB5N9RKG
s3://my-bucket/my-repo/manifests/A2WY69YBXKD8MXRY75Y0
s3://my-bucket/my-repo/manifests/AR3RRFVFK33M39M390TG
...
s3://my-bucket/my-repo/chunks/0000S2J66WH1DJG0XJD0
s3://my-bucket/my-repo/chunks/0002YB4FYZEEBQSJPY80
s3://my-bucket/my-repo/chunks/00032BVQNBV9XXTVXXHG
...These files form a tree of references: the snapshots point at manifests, and the manifests point at chunks (see Icechunk Spec). If you don’t have the manifests, the chunks themselves are indecipherable.
An additional feature of Icechunk is the ability to reference “external” chunks, located in a completely different bucket or cloud. This capability is commonly used to create VirtualDatasets, Icechunk repos which wrap existing NetCDF, HDF5, or TIFF files with a Zarr interface. However, the same mechanism can be used to create references from one Icechunk repo to another.
With these two ingredients we have the ability to create a metadata-only copy of an Icechunk repo which only exposes a subset of the original dataset.
The consumer receives only metadata files (snapshots and manifests), which point back to chunks in the provider’s bucket.
We can write these metadata files in such a way that the consumer has no idea what else might be present in the original dataset.
The consumer is granted scoped read-only access (with no LIST privileges) to the chunks/ directory in the provider’s repo by our credential vending machine.
Because of the cryptographically random IDs used for chunk names, it’s nearly impossible for the user to guess what else might be in there besides the chunks explicitly listed in their manifest. And even if they get extremely lucky by guessing a random ID, the contents and semantic meaning of the resulting object are opaque without additional metadata.
This mechanism can be used to subset by variable, and to slice arrays along chunk boundaries. The main limitation is that it can’t provide sub-chunk subsetting; the chunk (typically about 10 MB in size) becomes the atomic unit of data sharing. This is fine for most of our use cases.
This approach is the foundation of Filtered Subscriptions in the Earthmover Data Marketplace. A Filtered Subscription consists of four entities:
- A source repo, where the original data live (owned by the provider)
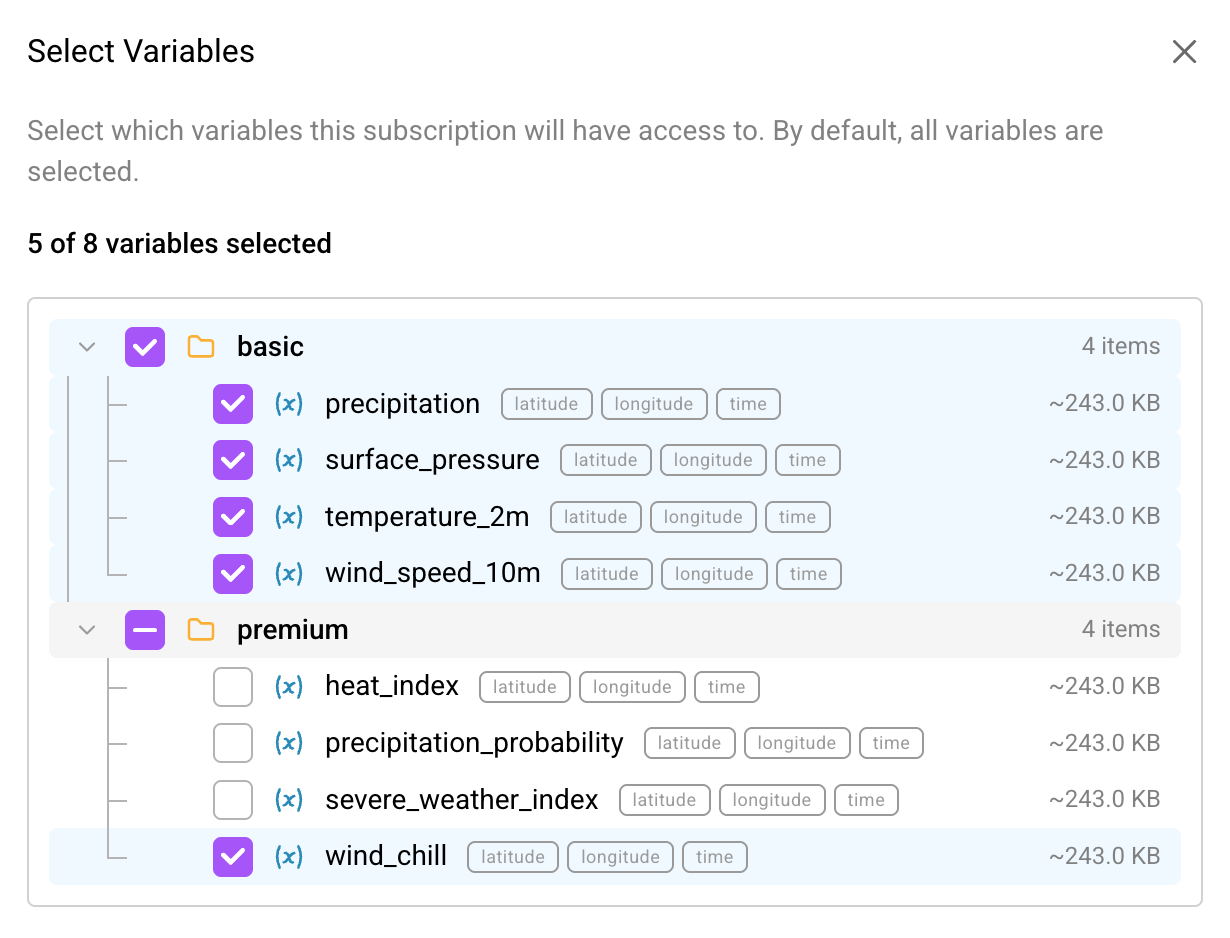
- A source filter - a set of rules about how to subset source data to expose in a Marketplace listing. For example, “only include variables
temperatureandsalinity.” This filter allows data providers to serve up subsets of the same repo as distinct data products in the Marketplace, as well as to reserve portions of a repo for their private use. - A target filter - a set of rules about the subset of the variables from the Marketplace listing to expose in a subscription. For example, “only include the variable
temperature, notsalinity.” The target filter is defined by the subscriber and is useful for managing costs. Subscribers can choose to only pay for the variables they care about, instead of subscribing to all the variables in a Marketplace listing., - A target repo, containing metadata files (snapshots and manifests) which reference the source repo chunks, producing a view into the original data as specified by the filter chain.

Data In Motion: Synchronizing Subscriptions
If the source dataset is static, then the problem is solved by applying the filter rules and generating the target repo metadata one time.
However, most of the datasets in the Earthmover Data Marketplace are the opposite of static! Our specialty is high-velocity weather forecasts, which may receive thousands of commits per day—typically appending along the init_time dimension.
(Brightband’s low-latency ECMWF forecasts datasets are a perfect example.)
In this case, we have to keep the subscriber’s filtered view in sync with the upstream changes—a much more challenging engineering problem!
This problem is solved by subsync, a critical piece of infrastructure for the marketplace.
Subsync has the following job:
- Listen for changes to subscribed datasets (source repos), via Arraylake’s existing repo change notifications.
- When a source dataset changes, find out who are the subscribers.
- For each subscriber and change: filter and propagate changes concurrently, fairly, and consistently.
Concurrently means “apply multiple changesets to multiple subscriptions to multiple listings.”
Fairly means “big repos can’t starve small repos.”
Consistently means “at no point is the repo invalid or has extra changes.”
This is a fun and challenging problem in distributed systems. Our engineering team came up with a robust and performant design, with the following components.
The Six-Stage Pipeline
Subsync is an event-driven pipeline, written in Rust, with six stages connected by a RabbitMQ message broker and coordinated through PostgreSQL. The pipeline follows a fan-out/fan-in pattern: one subscription fans out to multiple snapshots, each fans out to multiple manifests, then fans back in.
-
Propagate Source Change - A source repo change notification arrives. Subsync queries the Arraylake API to discover all active filtered subscriptions on that repo and publishes one message per subscription.
-
Compute Repo Diffs - For each subscription, Subsync opens both the source and target repos and diffs their operation logs to find new commits that haven’t been synced yet. It stages a snapshot of the source repo’s mutable metadata to S3 (since it could change while processing is in flight) and creates a “changeset” representing this batch of work.
-
Analyze Snapshot - For each new snapshot, Subsync determines which manifests are needed (only those belonging to arrays that match the subscription’s filter rules.) It tracks ownership so that when multiple snapshots share a manifest, the work isn’t duplicated.
-
Rewrite Manifest - This is the CPU-intensive core of the pipeline. Each manifest is fetched from the source repo and rewritten so that chunk references become virtual references pointing back to the source repo’s chunk storage. No actual chunk data is copied.
-
Rewrite Snapshot - Once all manifests for a snapshot are ready, subsync rebuilds the snapshot with only the nodes matching the subscription filter and writes it to the target repo. It also records per-array sync metrics (chunk counts, element counts, data types) for usage tracking and billing.
-
Commit Changeset - The final stage enforces strict temporal ordering: a later changeset will not commit until all prior ones are complete. This guarantees the subscriber’s repo never sees changes out of order, preserving consistency.
Multi-Tenant Fairness via Shuffle Sharding
Manifest rewriting (Stage 4) is the bottleneck, and a naive first-in-first-out queue would let one heavy subscription starve lighter ones. Subsync solves this with shuffle sharding, inspired by AWS’s approach: the manifest queue is split into 16 shards, and each subscription is deterministically assigned 2 of them. Two subscriptions only fully overlap with probability 1/120, providing strong probabilistic isolation between tenants.
Error Handling and Quarantine
In a system processing thousands of updates per day across many subscriptions, failures are inevitable—a transient network error, a corrupted manifest, a bug triggered by unusual data. Subsync treats failure as a first-class concern with a layered strategy.
Each pipeline stage has automatic retries with exponential backoff for transient errors. Messages that exhaust their retries are routed to a dead-letter exchange rather than being silently dropped, ensuring no change is lost without a trace.
When a subscription fails repeatedly, subsync quarantines it rather than letting it consume resources indefinitely or poison the pipeline for other tenants. The quarantine follows a state machine: a failing subscription enters a Waiting state with a backoff period. When the backoff expires, it moves to Retrying—if it fails again, it returns to Waiting with a doubled backoff. After enough cycles, the subscription reaches Exhausted, requiring manual intervention from the operations team. Workers check an in-memory cache to skip messages for quarantined subscriptions, so a single bad subscription never degrades throughput for everyone else.
This quarantine system ensures problematic subscriptions can be quickly identified and fixed, while healthy subscriptions continue to run smoothly.
Testing at Scale
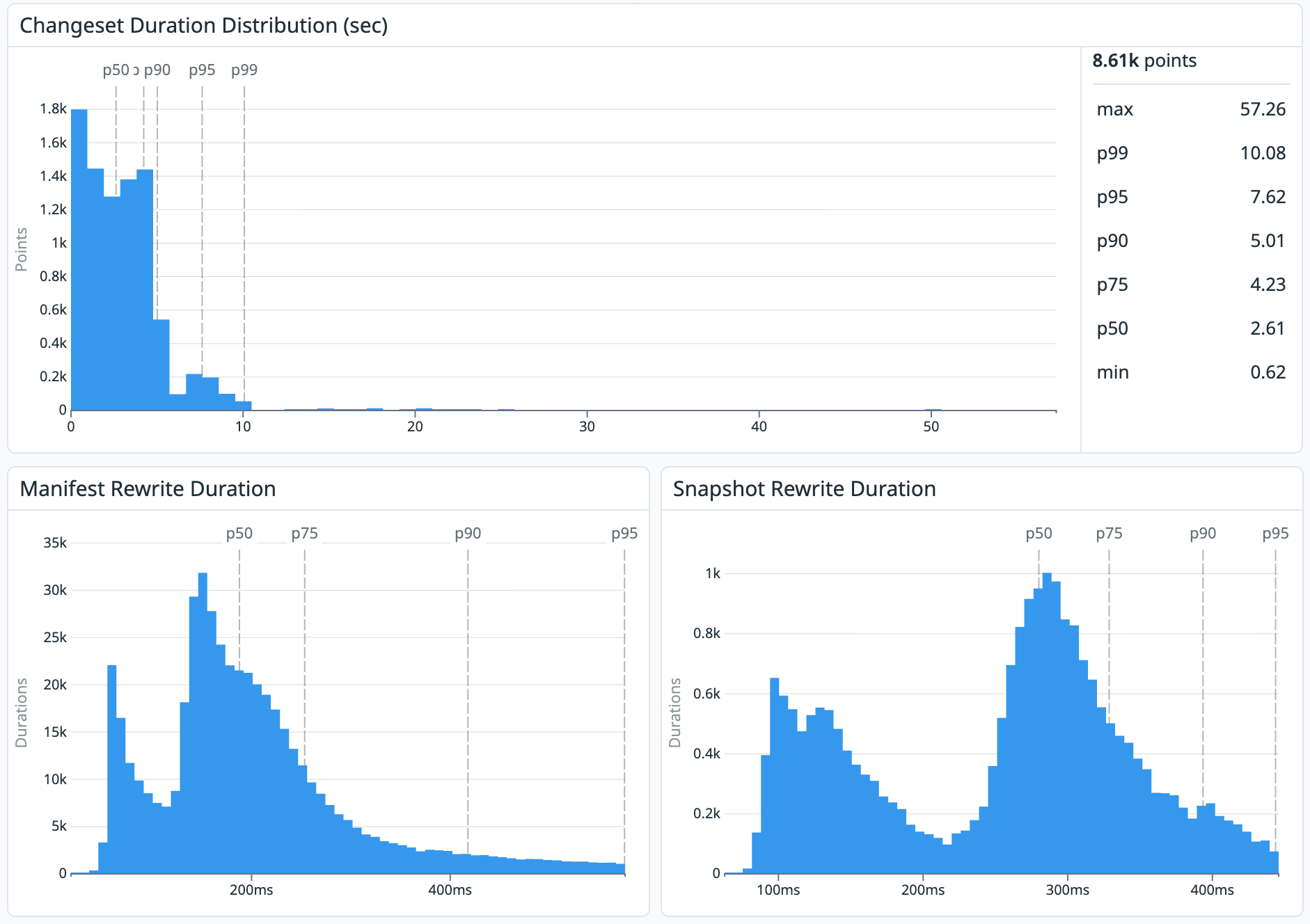
Before releasing, we tested Subsync heavily at scale using a wide range of data sources. The most challenging was a replica of Brightband’s low-latency ECMWF IFS listing which receives 1008 commits per day. We monitored the latency of the overall changeset distribution, as well as the time spent rewriting manifests and snapshots. The statistics below show a p50 latency of 2.61 s for changeset distribution, with a p99 of 10s. This means that subsync is doing its job well: keeping the subscriber repos in sync with the source with negligible additional latency. For subscribers with time-critical data needs, this is a game changer.
Impacts and Applications
Ok that was a pretty technical deep dive! 😅 Let’s zoom out… What does this enable?
Data Providers in the Earthmover Data Marketplace can now maintain a single ARCO data cube as their master “source of truth” for their data product. They can craft filtered subscriptions for their customers which include different subsets of this cube without processing or duplicating any data. Data consumers can access these subscriptions using cloud-native best practices, i.e. by hitting data directly in object storage, rather than proxied by a rate-limited API, enabling high-performance analytics and AI applications.
This allows data providers to focus on
- Making great data products
- Crafting packages and pricing to support different customer needs
…without heavy-duty data engineering and processing slowing the sales cycle. Creating a filtered subscription can be done with just a few clicks within the Arraylake platform.
Based on initial feedback from our design partners, we’re confident that Filtered Subscriptions is going to be a game changer for how geospatial data providers operate.
Roadmap
We are not done with Filtered Subscriptions. This release only supports a relatively limited form of filtering: by variable.
We have two important milestones ahead on the roadmap:
- Coordinate-based filtering - Define filters based on spatial or temporal coordinates. This enables providers to create, for example, custom subscriptions for a limited area of interest (i.e. “geofencing”). This is how most EO data providers prefer to sell and price data.
- Materialization of chunks to subscriber’s bucket - Some data users love the “virtual chunks” approach, wherein no chunk data are stored in the subscriber’s bucket. But sometimes the user really does need all the data (metadata AND chunks) to live in a different location than the provider’s storage. The most common reasons for this are performance (the user is training a model in Google Cloud
us-central-1and the provider data are stored in AWSeu-west-2) and compliance (the IT team mandates that all production data live in the company’s VPC). “Materialization” means that not just the metadata but the chunks too are transferred to the subscriber’s storage.
We anticipate shipping both of these features later in Q2 2026.
Getting Started
As a data consumer, you can head over the Earthmover Data Marketplace and start exploring data today.
If you’re interested in becoming a data provider, please fill out this short form. Data for filtered subscriptions must be stored in Icechunk 2 format, since Subsync relies on new Icechunk 2 features.