



Product Announcement: Teams in Arraylake
Teams is here for Arraylake paid accounts: group users and API keys, grant roles once, and every member inherits them. Group-level access management for growing data teams.
built for weather & climate|
Cloud-native tensor data management to accelerate problem-solving for our rapidly changing world.
Book a demoTrusted by leading institutions and ground-breaking innovators













Conventional data platforms struggle with multidimensional array data. Teams often build custom solutions, wasting months of development time. Earthmover provides a better approach to array data management.
Why tables fall short for tensor dataDeliver powerful and scalable data products, streamline operations, and reduce storage and maintenance costs



Earthmover's cloud native data architecture eliminates I/O bottlenecks and accelerates data-intensive applications.
Find, share, update, and audit your tensor data assets all in one place. Experiment and prototype quickly and safely with git-style data version control.
Remove bottlenecks from data exploration and product delivery with scalable APIs for querying large array datasets via OGC EDR, OpenDAP, WMS — or direct Xarray interaction.




Accelerate your roadmap with expert guidance from climate scientists and data engineers building the leading open source solutions and defining the modern workflow for multidimensional data. The team maintains critical open-source scientific Python packages, including Xarray, Zarr, and the Pangeo Project, used by teams at NVIDIA, NOAA, Google, Microsoft, and more.
Learn about open source leadershipModernize data operations so you can focus on what you do best.

Before (Data Swamp)

With Earthmover
Centralize data access, data cataloging, and git-style version control, so teams can collaborate in real-time and maintain data provenance. Simplify data pipelines, reduce code complexity, and avoid DevOps bottlenecks, even as datasets scale.
Most data science workloads are I/O bound. Accelerate model training, analytics, and decision making as you scale with a universal cloud-native tensor storage engine.
Explore and analyze datasets with your preferred tools. Easily operationalize and distribute datasets and data products with scalable, standards-compliant APIs.
Learn how customers use Earthmover to modernize data workflows for weather forecasting, climate modeling, environmental monitoring and more.
 Case Study
Case Study How an AI-native insurance company manages 130+ TB of satellite, weather, and geospatial data to model wildfire risk across millions of scenarios.
Learn more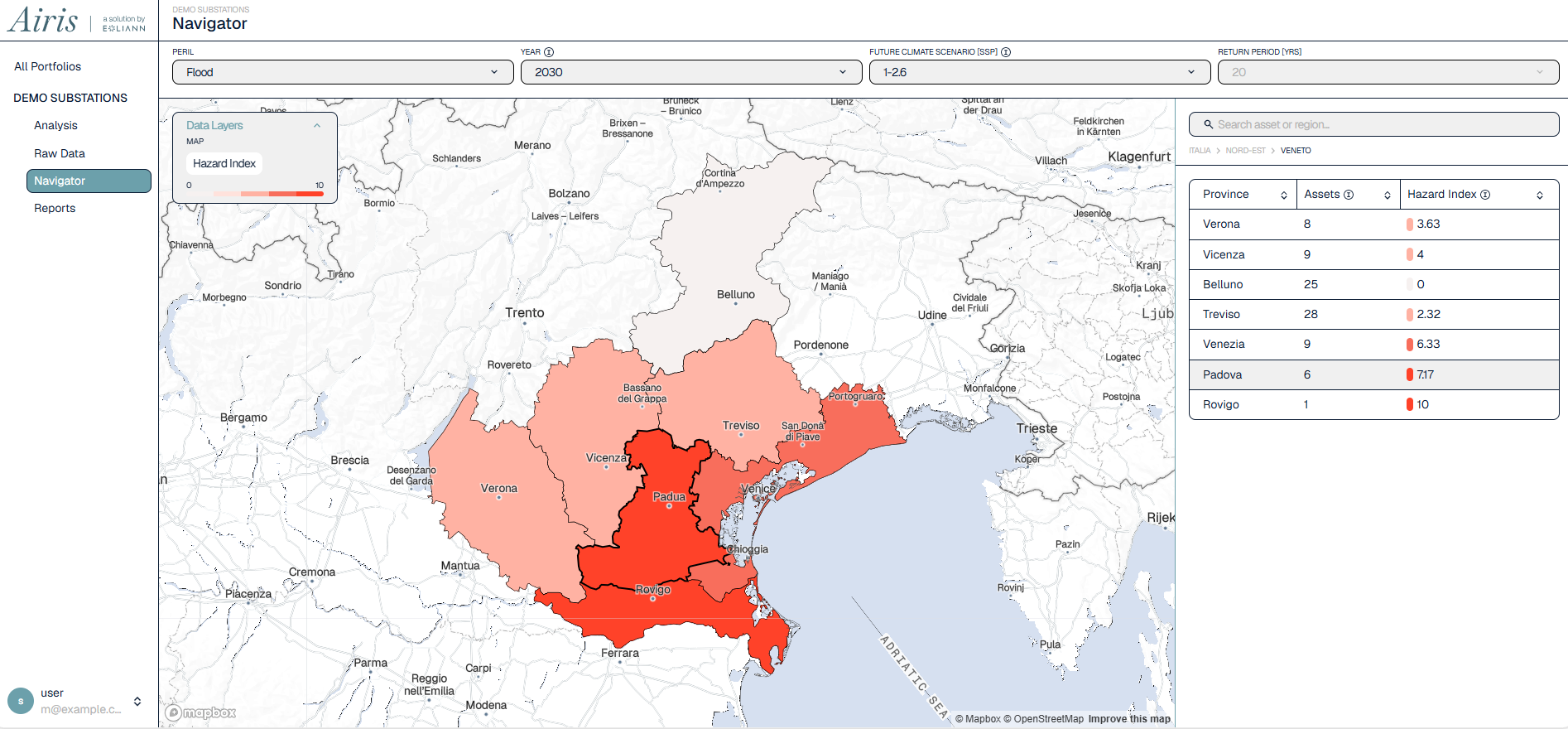 Case Study
Case Study How Eoliann replaced brittle file-based pipelines with a cloud-native platform to model physical climate risk on critical infrastructure.
Learn more
At Earthmover, we envision a world in which scientific data can be explored, visualized, analyzed, shared, and built upon effortlessly. We are providing a foundation for people and organizations to create new scientific knowledge and data-driven products which will help humans thrive in sustainable harmony with each other and with our planet.
Learn more about our team and missionTeams is here for Arraylake paid accounts: group users and API keys, grant roles once, and every member inherits them. Group-level access management for growing data teams.
A guest post from dynamical.org on how virtual Icechunk Zarrs complement materialized products to deliver low-latency, complete, and fast-access weather data — plus the low-latency NOAA HRRR dataset it describes, now on the Earthmover Data Marketplace.
GRIB data is notoriously hard to work with, so we made it easy to create virtual Icechunk stores from GRIB archives such as the NOAA National Blend of Models, allowing cloud-optimized access to GRIB data archives without copying the data.