The 3 Key Optimizations That Cut the Cost of AI Weather Forecasts by 90%


CEO & Co-founder
Note: this is the blog post version of a webinar we gave last month, summarized for brevity.
At Earthmover, we’re closely following the AI revolution in weather forecasting. Until recently, the only way to make an accurate global-scale weather forecast was to run an expensive, physics-based numerical weather prediction model on a supercomputer. The only people doing this operationally were government weather forecasting offices, militaries, and a few ambitious hedge funds like Citadel. But now, AI-based models like AIFS (from the European Center for Medium Range Weather Forecasting; ECMWF) can generate highly accurate forecasts on a single GPU, opening the door for industries from energy to agriculture to logistics to run their own custom predictions.
However, obtaining good performance from these models remains challenging. When running AI weather forecast models in the cloud, your most expensive resource—the GPU—can spend over 95% of its time sitting idle, waiting for data.
After we noticed several customers confronting this same problem, we decided to undertake a deep dive into optimizing AI weather forecast performance, focusing on a typical inference workflow. By leveraging our team’s expertise with cloud I/O and array-based data processing, we developed a production-grade pipeline that enables our customers to cut inference costs by nearly 90%.
It all came down to three key optimizations.
Watch the demo
Optimization 1: Stop Fetching Data, Start Pre-Processing It
The Problem: The standard AIFS workflow begins by downloading and parsing initial condition data from GRIB files for every single forecast run. In our tests, this took over two minutes, while the actual AI inference took just 10 seconds. The GPU was doing nothing for the vast majority of the job.
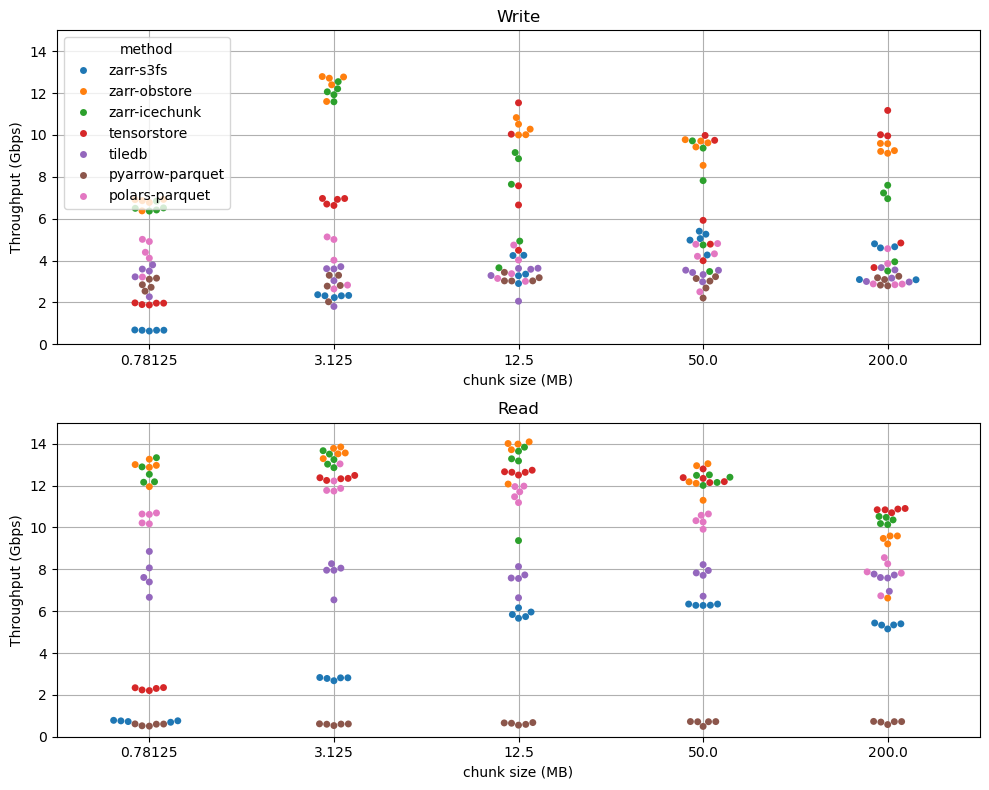
Our Fix: We implemented a one-time Extract, Transform, and Load (ETL) pipeline. Using cheap CPU spot instances, we pre-processed the raw GRIB data into Icechunk, Earthmover’s highly optimized, open-source, cloud-native format for array data. In the example, this Icechunk data is managed with our Arraylake platform, which takes care of data cataloging, access controls, but it also works with vanilla cloud object storage.
The Result: Data loading time plummeted from over 2 minutes to under two seconds. This was the single biggest factor in reducing costs and maximizing GPU utilization.
Optimization 2: Keep Computation on the GPU
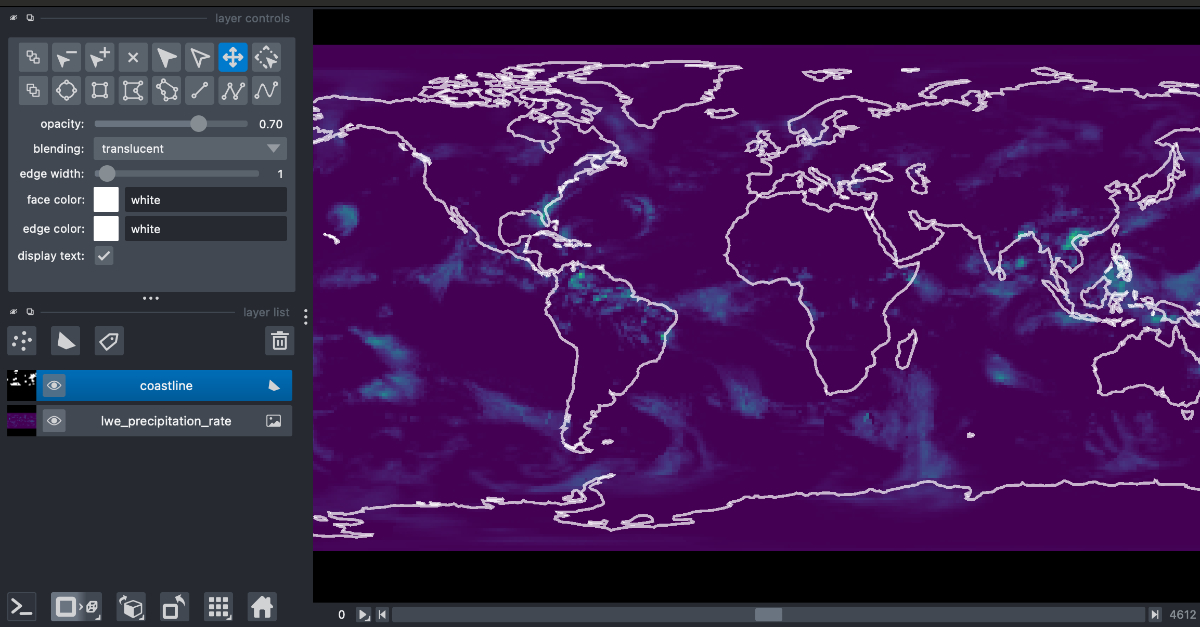
The Problem: The raw output of the AIFS model is on a Gaussian grid. For most real-world applications, you need to convert it to a standard latitude-longitude grid—a process called regridding. This is typically a CPU-bound task, requiring data to be moved off the GPU, processed, and then handled separately, adding time and complexity.
Our Fix: Since the regridding operation is fundamentally just linear matrix multiplication, we moved it directly onto the GPU. We were already paying for a powerful GPU, so we put it to work. The regridding now happens almost instantaneously as part of the core inference job, without ever leaving the GPU’s memory.
The Result: We eliminated the data transfer bottleneck and the extra processing time associated with regridding, making the entire pipeline leaner and faster.
Optimization 3: Write Outputs in Parallel, Not in Sequence
The Problem: A typical inference loop looks like this: run a forecast step, wait for it to finish, write the output to storage, then run the next step. Writing to storage is an I/O-bound operation that can be slow, once again leaving the GPU idle.
Our Fix: We interleaved the process using a multi-threaded queue. The main GPU thread runs an inference step and immediately places the result into a queue. A separate, lightweight CPU thread runs in parallel, pulling results from the queue and handling the slower task of writing them to storage.
The Result: The GPU is immediately freed to begin the next inference step without waiting for the I/O to complete. We effectively “hid” the latency of writing data, ensuring the GPU is running calculations almost continuously.
The Big Picture: From Idle to Optimized
By implementing these three optimizations, we transformed the efficiency of the entire process.
| Task | Original Workflow | Optimized Workflow |
|---|---|---|
| Data Loading | 2 minutes (on GPU node) | ~1 second |
| Regridding | ~20 seconds (on CPU) | <1 second (on GPU) |
| Writing Output | Sequential (blocks GPU) | Parallel (non-blocking) |
| GPU Utilization | < 5% | > 95% |
| Final Cost | 100% | ~10% |
The AI weather revolution isn’t just about better models; it’s about making them practical and affordable. With a smart, cloud-native approach to data, that future is here today.
Want to see how it works? We’ve open-sourced the entire pipeline in this GitHub repo.
Interested in learning how Earthmover can optimize your scientific data workflows? Contact us to learn more.
CEO & Co-founder