I/O-Maxing Tensors in the Cloud

CEO & Co-founder
The critical role of I/O in data science and AI/ML
For both analytics and AI workloads, fast I/O is the foundation of good performance. Most of these workloads involve fluxing a large amount of data from storage into RAM, and then to the CPU or GPU. In the cloud, where data reside on object storage, this step is too often a bottleneck–the storage engine can’t keep up with the compute, and the workflow becomes I/O bound. These I/O limitations have tremendous impacts on both infrastructure cost (think idle GPUs) and productivity (think data scientists scrolling Tiktok while waiting for calculations to complete).
With most cloud data platforms, tables are the core data structure. Instead, at Earthmover, we are laser focused on large, multidimensional arrays, a.k.a. tensors. (See tensors vs. tables.) Our customers, such as Brightband, Sylvera, and Kettle, are building AI-driven physical models of weather and climate for which tensors are both the input and output. For their sake, and for the sake of thousands of other teams out there, it’s imperative that we make tensor I/O as fast as possible. For the past year, we’ve been on a journey to make sure that our stack offers the best possible way to load tensor data from cloud object storage into memory. Today we’re excited to share our latest benchmarks which testify to the progress that has been made.
Bottom line: Zarr Python (using either Icechunk or Obstore as the storage engine) is now able to fully saturate the network between EC2 and S3, resulting in the physically maximum possible throughput when reading and writing data. This holds true in the presence of compression and over a wide range of chunk sizes.
The Benchmark
Our benchmark is simple: write to S3, and then read back, a large tensor while varying the chunk size over a wide range of values. Results are measured in network throughput (Gbps) and can thus be directly compared to AWS’s published EC2 instance network bandwidth data. Anything short of the published value means there is still performance on the table. If your storage engine can’t do this well, it won’t be fast at anything fancier, like data science or AI/ML.
We compared the following software stacks
- Zarr Python + s3fs: this is the default configuration most users are familiar with, using the s3fs library to talk to S3.
- Zarr Python + Icechunk: replacing s3fs with Icechunk, Earthmover’s open source Rust-based storage engine for Zarr. In addition to fast I/O, Icechunk offers ACID transaction, data versioning / time travel, and integration with VirtualiZarr for zero-copy ingestion of NetCDF, HDF5, and Grib files.
- Zarr Python + Obstore: replacing s3fs with Obstore, an alternative Rust-based I/O layer for Zarr created by Kyle Barron on top of the object_store crate.
- Tensorstore: Google’s tensor storage engine, written in C++, which reads and writes Zarr Arrays. Used internally for checkpointing Gemini training runs.
- TileDB Embedded: another great open-source tensor storage engine.
- PyArrow + Parquet: While Arrow doesn’t support arbitrarily chunked ND-arrays like the libraries above, this remains an interesting comparison. Since our test data is 1D, it maps fine to the Arrow model. We store the entire array into a single-column Parquet file, equating the chunk size with the Parquet row group size.
- Polars + Parquet: A different implementation for the same format.
Here are some additional details about the test setup:
- We ran our tests on a range of AWS EC2 m8g instances, up to an m8g.24xlarge instance with 40 Gbps of network bandwidth. We used larger arrays for the larger instances with more memory and bandwidth.
- All EC2 instances and S3 buckets were in the AWS us-east-1 region.
- Where appropriate, we set the number of threads equal to the number of CPU cores in the instance.
- We ran each test 5 times to get a bit of a distribution.
- We used int64 random data with ZSTD compression to create a “worst case scenario” for compression– we get all of the CPU overhead of compressing and decompressing data with none of the benefits, since random data are inherently incompressible. (Below we show how using compression with real data enables us to go beyond network limitations!)
- We used Coiled to deploy our code to EC2. All benchmarks are open source and available, along with the software environment, in a GitHub repo.
- No Dask was used in any of the benchmarks. All of these libraries now implement their own internal concurrency for I/O.
- We did not control for S3’s dynamic prefix sharding, which introduces some time dependence in S3’s response rates. This is likely responsible for at least some of the spread seen in results.
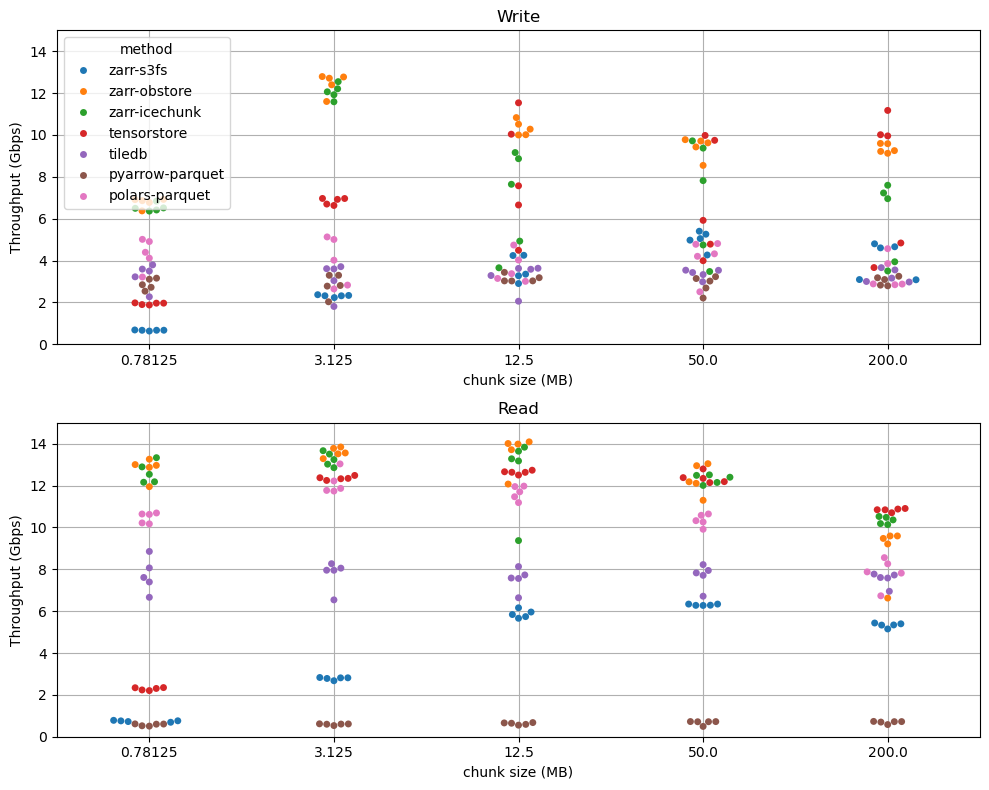
Example results are shown below for a m8g.8xlarge instance and an array with 3.2 GB of data. This machine has 15 Gbps of network bandwidth. Plots use a Seaborn swarmplot style to show the distribution of values.
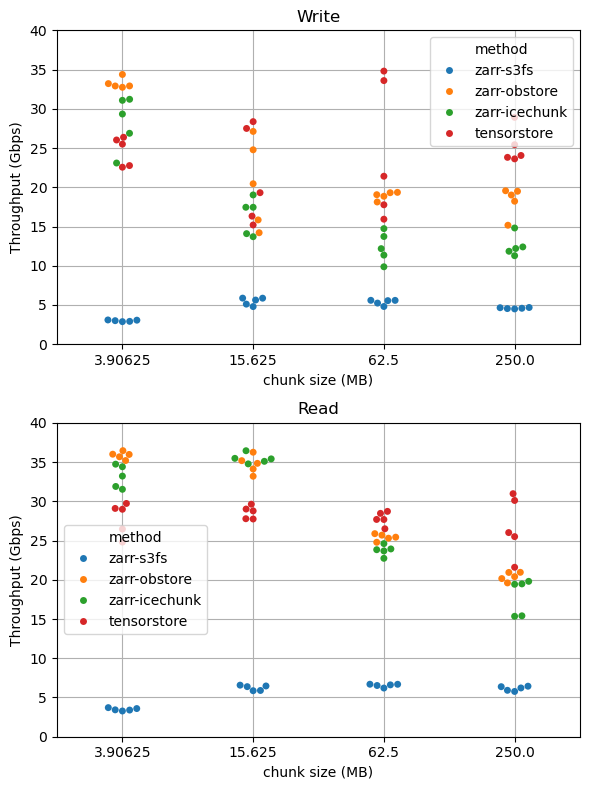
Here are the results on a larger machine: m8g-24xlarge with 40 Gbps of network bandwidth, using a 16 GB array. (We only ran a subset of chunk sizes and libraries on this one.)
Key Results and Observations
We summarize the results with the following observations:
- Zarr with either Icechunk or Obstore as the storage engine achieves the absolute fastest numbers for both reading and writing. On the m8g.8xlarge instance, with 15 Gbps of bandwidth, both achieve 13 Gbps write and 14 Gbps read throughput. On the m8g.24xlarge instance, with 40 Gbps of bandwidth, they achieve 35 Gbps write and 37 Gbps read throughput.
- Tensorstore performance is comparable, albeit with slightly lower at peak read throughput and a qualitatively different dependence on chunk size.
- Zarr with s3fs is 2-10x slower than with the Rust-based backends. It struggles particularly in the “many small chunks” regime.
- The overhead of ZSTD compression is negligible. Tests with no compression (not shown) gave similar results.
- There is much more spread in write speed than read speed. This may be due to S3’s dynamic prefix sharding.
- The Icechunk and Obstore experiments show less sensitivity to chunk size than Tensorstore. Remarkably, both Icechunk and Obstore produce nearly the same read throughput for 800 KB chunks as they do for 50 MB chunks. This is important because smaller chunks result in faster random access, but without a performance penalty on throughput.
- The optimal chunk size for Icechunk is 3-15 MB.
- TileDB tile size (here set equal to the Zarr chunk size) does not meaningfully impact throughput. This is because TileDB batches data writes into “fragment” files which are not dependent on tile size. TileDB maintains a respectable throughput across the full range of tile sizes
- Although we expected the Arrow / Parquet stack to be able to fully saturate the network bandwidth, we could not get PyArrow to read our single-column 3.2 GB Parquet file from S3 fast. It delivered an abysmal 0.5 Mbps throughput. (Paradoxically, here PyArrow is about 8x faster at writing than reading.) We tried varying the row group size parameter, but it had no effect. Digging deeper, we learned that PyArrow does not parallelize reads over a single column.
- Polars, however, does parallelize over row groups. And as a result, Polars gives great read throughput–around 12 Gbps, just shy of Icechunk / Obstore and on par with Tensorstore.
Overall, this is really great news for the cloud-native scientific data community. Zarr is emerging as the consensus choice for storing large, complex scientific datasets in cloud object storage, with adoption from organizations as diverse as Google, NASA, and the Copernicus Sentinel satellite mission to Open Microscopy Environment. However, until recently, it wasn’t providing optimal performance for this simple but critical workload. Now Zarr users can feel confident that their cloud I/O is occurring at the physical limit of the network (or even beyond; see below). This is critical particularly for AI workloads with expensive GPUs in the loop.
Pushing Beyond Network Bandwidth with Compression
As noted above, the results with random data represent a “worse case scenario:” all of the costs of compression with none of the benefits. So what about real data?
We applied the same benchmark to reading surface pressure data from Earthmover’s ERA5 Sample Data, stored in Icechunk in us-east-1. Here the code is trivial. Try it yourself! (Just make sure you’re running in AWS us-east-1.)
On our modest m8g.8xlarge instance, we got 28 Gbps. This is nearly 2x the available network bandwidth! How is this possible? Simple: the compression ratio of this data is about 2, so we only had to move half the amount of data over the network. More modern compressors, like pcodec, may be able to get even higher compression ratios!
The Zarr / Xarray Performance Journey
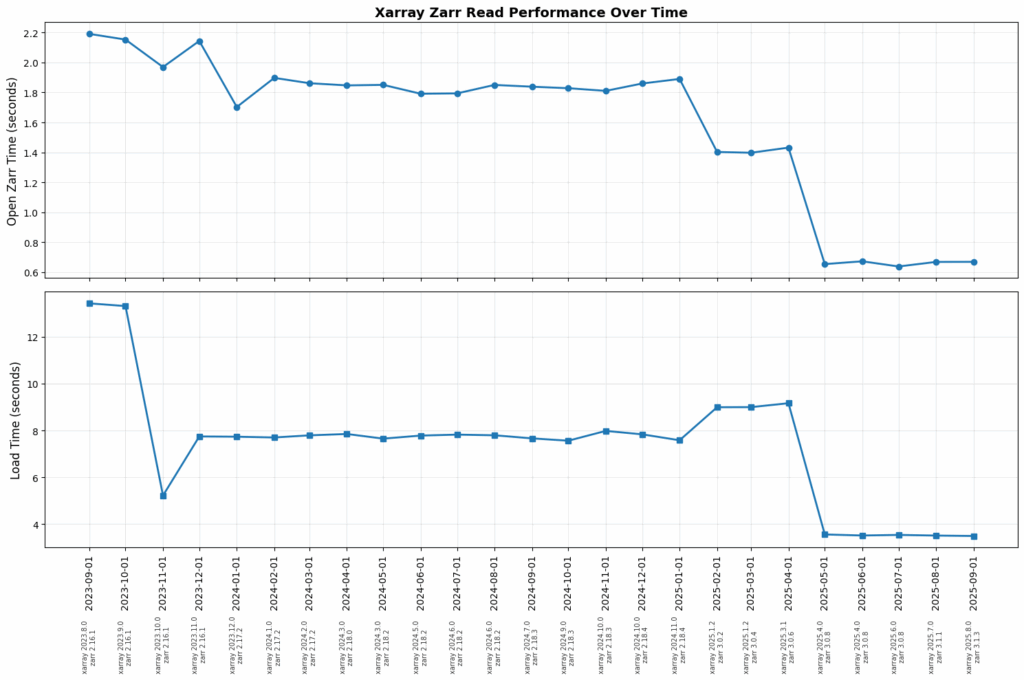
Two years ago, Zarr Python performance was in a pretty bad place. No one was getting anywhere close to network-saturating I/O performance. It was conventional wisdom that Tensorstore was the only option for performance hungry teams. Today that’s no longer the case; peak performance is now possible with Zarr Python.
This improvement is the result of a focused and sustained effort by Earthmover and collaborators (big shoutout to Davis Bennet!) to supercharge how Zarr (and Xarray) handle data in the cloud. We painstakingly refactored Zarr Python with the following principles:
- Aggressively limit unnecessary I/O calls. Zarr was originally written for file storage, where an extra small read operation on the filesystem costs 1 ms. On object storage it’s often closer to 100 ms. We added logging hooks to Zarr Python to detect and then eliminate any unnecessary I/O operations from typical workflows.
- Asynchronous I/O everywhere. We rewrote Zarr Python with asyncio at its core. This was one of the most important features in the Zarr Python 3 major release. Asyncio enables much more efficient concurrent interaction with high-latency remote storage such as S3.
- Streaming I/O and codecs. The codec pipeline in Zarr Python 3 starts decoding chunks while others are being fetched, using a streaming architecture.
- Threadpool for codec execution. While I/O benefits from an asynchronous event loop, chunk encoding / decoding is CPU-bound. Zarr Python offloads codec execution to a dedicated threadpool.
- Write the low-level storage layer in Rust. S3fs ultimately relies on Python’s HTTP implementation, while both Icechunk and Obstore use a Rust-based implementation. This appears to be critical for squeezing all of the performance out of S3. (Note: things may be changing with free-threaded Python.)
The result of this consistent focus over time can be seen in the following graph, showing the cost of opening and reading the same Zarr dataset from using Xarray over the past two years. Both metrics have improved by 3-4x during this time.
Caveats
Benchmarks are always biased! We did our best to optimally configure each library we used, but inevitably we were probably best at configuring the stack we work on every day. We set Tensorstore’s S3 concurrency to the number of CPU cores. TileDB includes defaults which automatically scale concurrency with the system size, so we didn’t touch this configuration. Zarr Python 3 is noteworthy in that it has a separate work queue for asyncio requests and threadpool for CPU-bound chunk decompression; we use a large amount of async concurrency (128) while setting the threadpool size to the number of CPU cores.
Fortunately, this is a benchmark that everyone can win! It’s bounded by the network speed. We’re happy to update our results to include better configuration for these libraries. Just leave us a comment or DM.
We also did not explicitly profile the CPU and memory utilization of each library. We simply concentrated on the number that matters most to our users: raw throughput. Of course, it’s ideal to achieve this with as little CPU and memory utilization as possible. We may dig into this in a follow-up.
We only looked at AWS S3. AWS is where 80% of our customers are today. But there are lots of other great object storage services out there, from Google Cloud Storage to Tigris. In the future, we might expand our benchmarks to cover more object stores.
Finally, we realize of course that there is more to end-to-end performance than this simple I/O benchmark. There are so many powerful techniques used by advanced query engines for optimizing performance which are still unimplemented in Zarr Python. The point of this post was to focus on a dead-simple but essential task of reading as much data as fast as physically possible on a single big machine. Without first nailing this, other optimizations have little point. A future blog post will focus specifically on optimizing data loaders for AI model training.
The Takeaway
Fast I/O is at the core of modern analytics and AI workloads. If you’re doing either of these in the cloud using tensor data stored in S3 and you’re not loading data at the maximum speed the network will support, you’re leaving performance (and therefore time and money) on the table.
At Earthmover, our view is that Xarray, Zarr, Icechunk together offer the best all-around developer experience for working with tensor data in the cloud. Xarray brings the high-level data model and API loved by data scientists. Zarr brings the chunked, compressed storage model. And Icechunk brings ACID transactions, data versioning, and a high-performance, Rust-based I/O layer. The benchmarks shared in this post show that this stack also offers best-in-class performance for I/O bound workloads, a key criteria for today’s scientific AI teams. Top it off with the incredibly supportive community around these tools, and the choice is really a no-brainer.
Of course, fast I/O is only the beginning. At Earthmover, we’re building the modern cloud platform for scientific data management on the open source foundation of Xarray, Zarr and Icechunk. Our platform provides enterprise-grade multi-cloud data catalog and data governance; high-performance, standards-based geospatial APIs for data integration and visualization; and, coming soon, a data marketplace where you can access analysis-ready, cloud-optimized weather and climate datasets from the industry’s top data providers. 🤭 Oops, did we just let that slip? Stay tuned, this is just the beginning…
CEO & Co-founder






