Case Study: ALIVE at The University of Wisconsin-Madison

CEO & Co-founder
Background
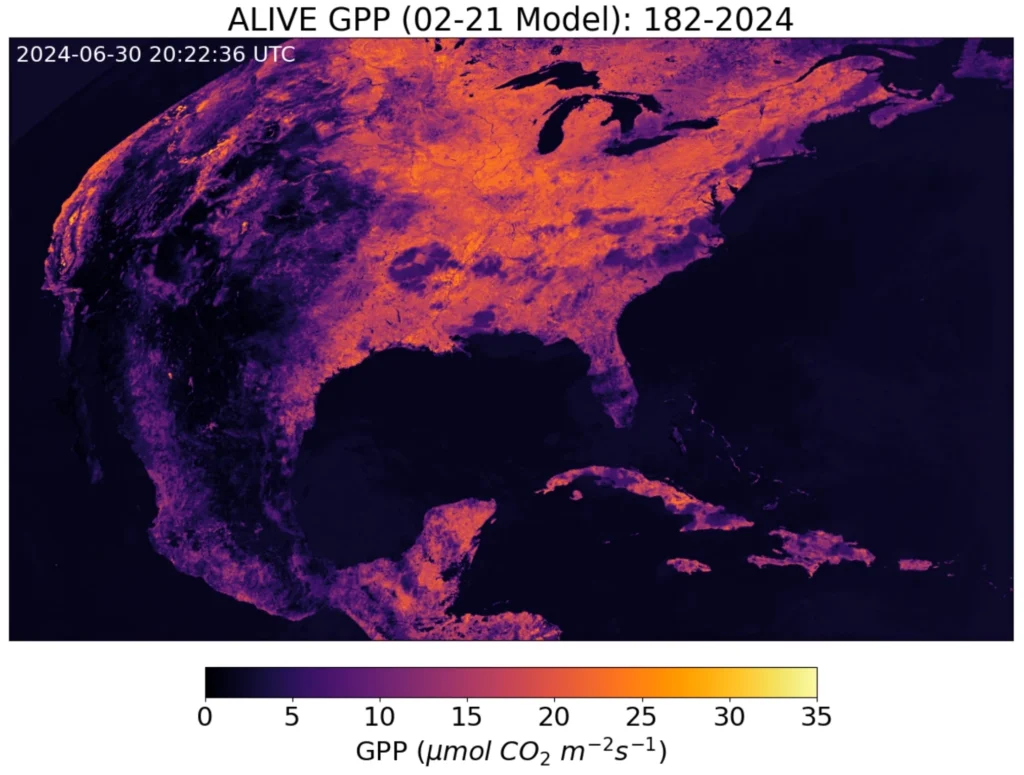
The University of Wisconsin-Madison is home to a research team called Advanced Baseline Imager Live Imaging of Vegetated Ecosystems (ALIVE). The team, working remotely and led by Prof. Paul Stoy, PhD, is building a gradient-boosting regression model using geostationary satellites to estimate terrestrial carbon and water fluctuations in near real-time. The team trains its models using GOES-R and other public satellite and meteorological datasets.
In trying to process this data, they ran into the central problem when working with raster data for time series analysis – the data’s format, mainly NetCDF and GeoTIFF, is not conducive to time-series analysis. This experience inspired them to strive to create output datasets that are analysis-ready for various applications.
During AMS 2024, ALIVE researcher Danielle Losos connected with Ryan and Joe and explained the team’s data challenges. Ryan and Joe suggested that the solution lay in adopting the Zarr data model and Arraylake as their data catalog. The ALIVE team spent some time learning Zarr and about the Arraylake architecture and language. While there was a bit of a learning curve, overall, it was easy to pick up.
Arraylake Impact
The ALIVE team has found Arraylake’s ACID transactions and version control to be extremely useful. They allow the team to experiment freely and revert data to a previous version should an experiment fail or in the case of human error. The rich commit history has allowed the team to seamlessly collaborate on their data, which is especially critical being a remote team. They also find the hierarchical organization within repositories to be crucial in understanding their data and its structure.
From ALIVE’s team:
“Arraylake has made our project demonstrably better – the data is more accessible, the workflows make more sense. Arraylake takes our work and makes it more real, tractable, and dynamic. It’s the thing that takes our project and makes it useful.”
Paul Stoy, PhD ALIVE Lead
CEO & Co-founder