Announcing Flux: The API Layer for Geospatial Data Delivery

CEO & Co-founder
TLDR
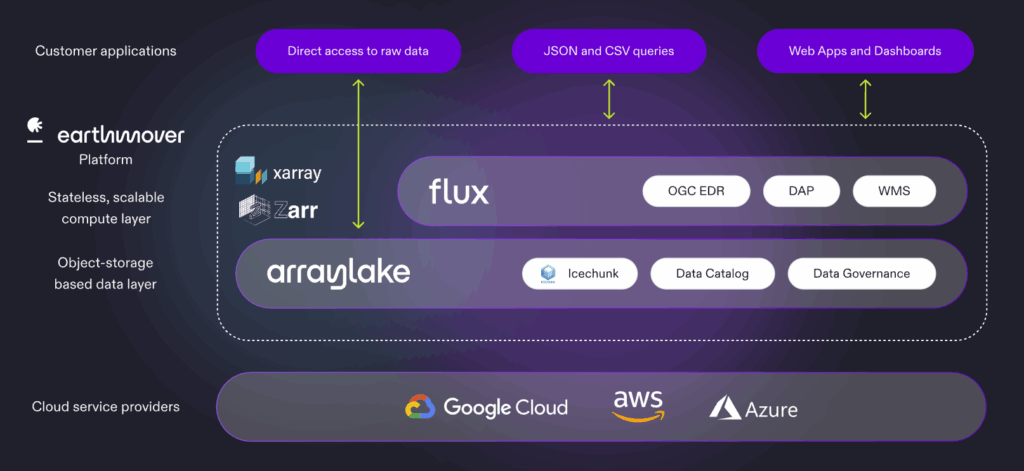
Earthmover’s new product–Flux–adds a whole new layer to our platform. Flux allows you to serve geospatial data from Arraylake via standard API protocols–including WMS (web map service), EDR (environmental data retrieval), and DAP–enabling frictionless integration with GIS applications, web applications, and downstream databases. Flux enables our users to focus on building great data products instead of managing and scaling complex infrastructure. Sign up for the webinar to learn more!
Motivation: The “Last Mile” of Data Delivery
Earthmover’s customers are teams creating rich scientific data products using cutting-edge data science and AI/ML. These teams store and manage their data in our Arraylake platform in the open-source Zarr / Icechunk format. After onboarding our first few customers, we started noticing a pattern. Everyone was building basically the same type of JSON-based API to query their Zarr data cubes and deliver data to downstream applications.
This makes sense. Zarr was designed to support high-performance analytics and AI/ML workloads. Most data teams working in weather, climate, and earth observation are using Zarr as their primary storage for multi-terabyte data cubes. But many applications (e.g. front-end apps) just need a tiny piece of data from these massive cubes. Common use cases for this type of service include:
- Extracting time series from a gridded weather forecast dataset at the locations of solar panel sites for renewable energy supply forecasting
- Querying a historical climate dataset at specific asset locations to build a climate risk profile for a company’s assets
- Extracting specific forest parcel locations from an Earth-observation data cube to monitor deforestation
To achieve this, we saw engineers across multiple different teams building back-end APIs with the following basic structure:
- Accept a query with coordinates encoded in the query string (e.g. lon=45&lat=23&variable=temperature)
- On the back end, translate this to an Xarray query against a Zarr dataset in object storage
- Return a JSON response with the result
🙋 Raise your hand if you’ve built an API like this before!
Here’s the problem: while hacking together a simple prototype is straightforward, now the team of data scientists has a new service they have to maintain. The prototype soon hits limitations–either in terms of functionality (“can you add a new field to the schema?”) or scalability (“can it handle 1000 requests per second?”) As the underlying data product matures, the company now wants to use the API to deliver data to their customers, bringing in new requirements for authentication, authorization, logging, and billing. The scope balloons, and before long, this team is now overwhelmed with building and maintaining the service, rather than doing more differentiated, valuable work of building the data product itself.
Furthermore, these home-grown APIs tend to be developed in an ad hoc way, limiting interoperability with outside tools and systems. The team has essentially defined a new API standard and now must adapt all their tooling around that standard. (Obligatory XKCD standards cartoon reference.)
Standards to the Rescue!
After seeing several teams go through this same process, we began to realize that virtually all of these use cases were well served by an existing API standard: the Open Geospatial Consortium’s Environmental Data Retrieval (OGC EDR).
Environmental Data Retrieval Standard provides a family of lightweight query interfaces to access spatio-temporal data resources by requesting data at a Position, within an Area, along a Trajectory or through a Corridor.
As long-time open source developers, we’re huge believers in standards. Standards make life easier for developers by defining interfaces between system components. In the case of EDR, the standard describes how to specify the location[s] of interest in the query string (as WKT geometries), how to format the outputs (as CoverageJSON, GeoJSON, or NetCDF), and dozens of other common parameters and options that typically arise in this type of workflow.
So we decided to implement an EDR service on the platform side that our customers could use instead of building and operating their own ad-hoc JSON APIs. This started out as an experimental private beta with a few select customers. It turned out to be a hit! EDR turned out to be more flexible than the in-house API specs. And as an added bonus, it’s compatible out of the box with tools like QGIS.
Once we had EDR running, we realized that the infrastructure we had built to serve EDR requests could easily handle other protocols and use cases. The vision for Flux was born: an infrastructure service which seamlessly translates Zarr data in object storage to a wide range of standards-compliant geospatial API protocols.
Next on the list was dynamic map tiles. Nearly everyone we talked to was interested in getting their Zarr data onto a slippy map for viewing in a browser or desktop GIS application. While it’s technically possible to build Zarr datasets that can be read directly from the browser, this requires a highly specialized dataset structure (e.g. specific encoding, CRS, and chunking). Instead, we implemented a Web Map Service (WMS) service. This service handles the slicing, reprojecting, and shading on the backend, flexibly serving up maps and map tiles using one of the web’s most widely supported protocols.
The final service in this release of Flux is another classic: Data Access Protocol (a.k.a. DAP, OPeNDAP). DAP is widely used in the scientific data community as a remote access protocol compatible with the NetCDF data model. DAP enables general-purpose remote access and subsetting of datasets and is widely supported by numerous geospatial and earth-science tools, including the NetCDF library itself. DAP via Flux brings our customers the ability to query Arraylake data in their programming language of choice, including R, Julia, Java, C / C++, and even Fortran! DAP is also supported in ArcGIS, QGIS, MATLAB, IDL, NCL, Ferret, Panoply, and many other specialized applications.
The great thing about the way we’ve built Flux is that the model is easily extensible to support other API standards. Are you interested in something beyond EDR, WMS, or DAP? Please reach out and let us know. We’ll put it on the roadmap!
Cloud-Native Architecture
While many of the protocols supported by Flux have been around for decades, the system architecture is decidedly modern. We designed Flux to take advantage of all of the best practices and design principles for scalable, cloud-native data systems. Specifically:
- All persistent data are kept in cloud object storage. Specifically, data are stored in the Icechunk format and managed via Arraylake, the data catalog and governance layer of our platform. Arraylake tracks the locations of Icechunk datasets within object storage and manages credentials and access controls. (The same interface customers use to query their data directly from Python is used internally by Flux.) Preparing data for use with Flux is as simple as writing an Icechunk dataset with appropriate geospatial metadata and flipping a switch to enable the service.
- All requests are handled by an auto-scaling pool of stateless workers. Icechunk’s high-performance I/O helps on the backend by efficiently scanning and loading data from object storage to worker memory for processing. Because there is no state within these workers, we can dynamically add and remove them as needed in response to fluctuations in load. This enables Flux to scale from serving sporadic requests to a single developer to serving thousands of concurrent users in a production environment without breaking a sweat.
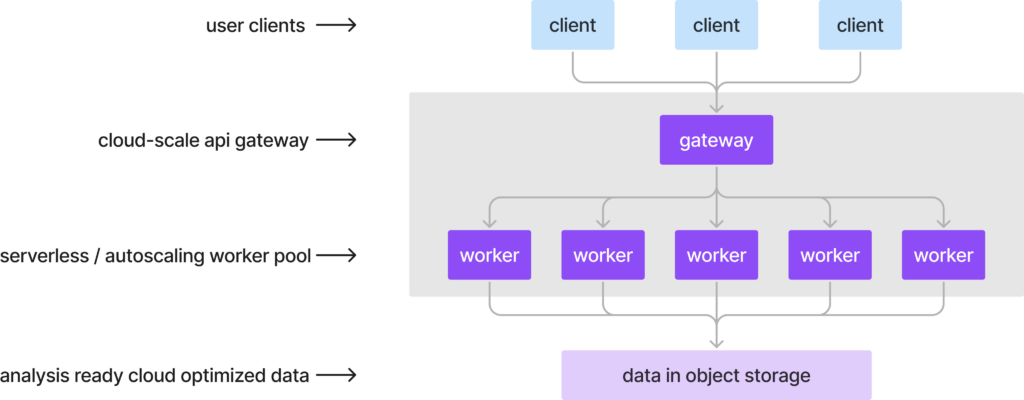
This architecture is a key selling point for Flux. Existing geospatial data servers such as GeoServer or THREDDS were designed for the on-prem era, where the data to be served are attached to the server instance via a POSIX filesystem. While effective for small data, this approach doesn’t scale well, since it requires that either the data be replicated across a fleet of servers or a cluster with a fancy distributed filesystem.
Our CTO Joe Hamman gave a talk at AGU 2024 with a deep dive into the Flux system architecture and scalability benchmarks. Check it out if you want to dig deeper.
Observability and Access Controls
In addition to providing scalable performance, Flux solves other key problems that teams encounter when delivering data in production via APIs.
- Authentication and Authorization - Flux uses Arraylake’s identity and access control system to authenticate requests (using HTTP basic auth or tokens) and authorize access to specific datasets. This enables teams to implement a unified data governance policy across all modes of data access, including the secure delivery of private data to external clients. (Or Flux services can be configured for fully public, non-authenticated access.)
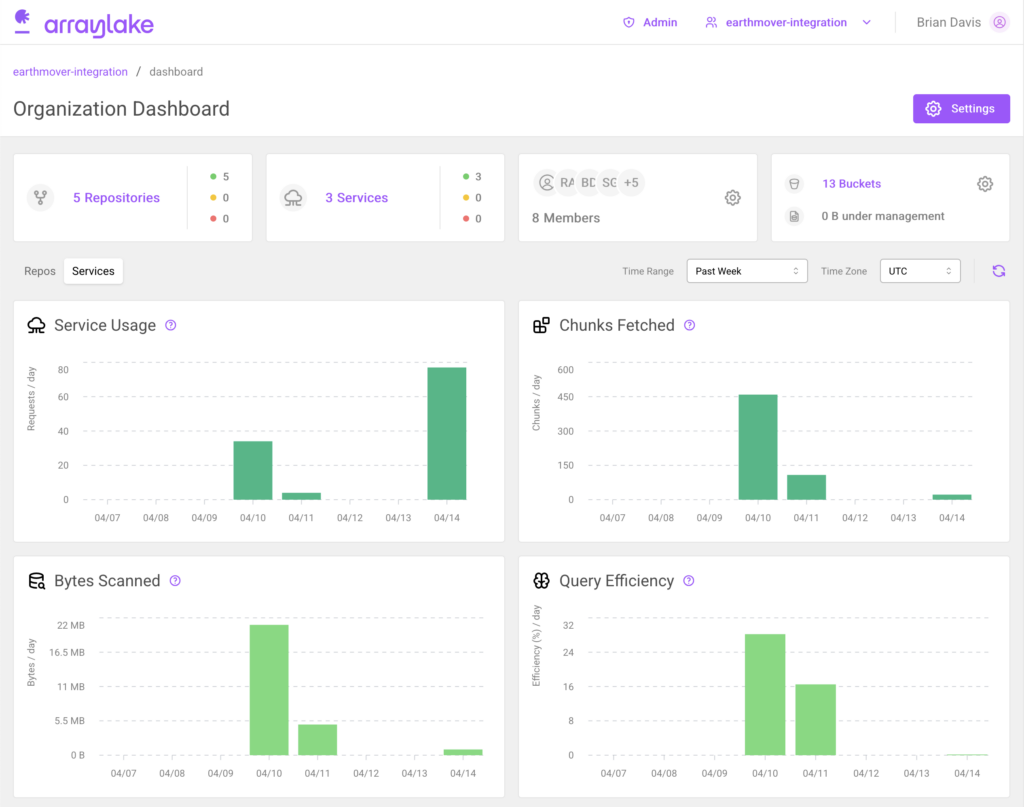
- Observability - Flux exposes detailed service logs (to help understand what’s going on under the hood and debug any issues with queries). It also generates useful metrics on request data volume and latency and exposes these via a user-friendly dashboard. These metrics can be used to understand the usage patterns of different datasets.
These sorts of enterprise features are rarely prioritized in home-grown backend services. But they’re necessary components of a secure, reliable, production-grade data delivery system.
Real-World Impacts
We are grateful to the early adopters who provided feedback and helped us design Flux, including Pelmorex, Sylvera, and Kettle. It’s extremely gratifying to see Flux in production today, helping our customers execute faster.
From a business perspective, the core value proposition of Flux is to enable teams to deliver data products more quickly–, and at lower engineering cost and complexity–, than with alternative solutions. For some teams, this translates into faster time-to-market with a new AI-based forecast product. For others, this means freeing up data scientists and engineers to focus on more strategic development priorities, rather than maintaining infrastructure.
Here’s what one of our Flux users had to say:
Flux allows us to get immediate feedback from customers as we design our data offerings, without having to deploy new infrastructure. This allows us to experiment with product market fit without a significant engineering investment.”
Jon Weisbaum, Director of Meteorological Engineering at Pelmorex
Flux can accelerate development in a wide range of verticals which rely on weather, climate, and Earth-observation data for research and operations, including energy, finance, insurance, climate risk, carbon accounting, and environmental monitoring. Flux also has a role to play in the public sector, where APIs like DAP are used extensively in agency data delivery systems.
We started Earthmover because we knew that working with scientific data was too hard and slow. Scientific data teams are burdened with building and maintaining bespoke and inefficient data systems rather than doing innovative science. We believe that, by leveraging open standards, open source, and cloud-native data systems, we can all go farther and faster. Flux is an important milestone on our journey towards making scientific data flow freely and empowering these teams to do what they do best: building great data products.
Getting Started with Flux
Is your team struggling to deliver geospatial data effectively and in the market for a managed infrastructure solution? As of today, Flux is now in general availability within the Earthmover platform (documentation). To learn more about Flux and Earthmover’s vision for the future of Earth-system data infrastructure, watch the webinar recording, “Accelerating Data Product Delivery with Flux”. Or reach out to request a personalized demo and consultation about how Flux might be able to help your team.
CEO & Co-founder