Arraylake Now Available in Private Beta

CEO & Co-founder
At Earthmover, we believe that scientific data are key to solving humanity’s greatest challenges. And we know that scientists today are struggling with tools that don’t understand scientific data formats and data models.
For the past year, we’ve been hard at work building a platform to transform how scientists interact with data in the cloud. Today, we are thrilled to announce the launch of Arraylake in private beta.
Arraylake is a data lake platform built around collections of multidimensional numerical arrays (a.k.a. ND-arrays, tensors)—the native data model of physical, biological, and computational sciences, not to mention deep learning. Given the centrality of tensors to so many disciplines, we were frustrated that they are poorly supported by today’s cloud data infrastructure. Existing cloud data warehouse and lakehouse products focus almost exclusively on tabular data, relegating ND-arrays to the purgatory of “unstructured data”. In practice, most teams working with arrays in the cloud today are storing their array data directly in object storage (e.g. AWS S3) using file formats like TIFF, HDF5, NetCDF, or Zarr and rolling all of their own infrastructure to ingest, catalog, and compute on their data. This mode of working is an enormous burden on data scientists and engineers and, viewed holistically, a massive drag on our progress toward solving humanity’s greatest challenges. The problem is particularly severe in the rapidly growing climate tech sector, where companies are struggling to use weather, climate, and satellite data in operational systems.
Imagine if every e-commerce company had to first build their own database before they could start building anything else! That’s basically where we are at today with systems and applications that use scientific data.
We have designed Arraylake to solve some of the key challenges scientific data teams face when building production systems, while simultaneously aiming to create minimal disruption to existing workflows and data pipelines. We do this by embracing the open standard Zarr as our core data model. Zarr users already know about the cloud-native access patterns and excellent scalability supported by this format. However, storing Zarr directly in object storage has some limitations. Here are the main problems practitioners face today, and how Arraylake solves them.
Arraylake Features Overview
Data Catalog
Problem: The user experience for browsing, exploring, and discovering data on object storage is very poor. Serious teams usually need a secondary catalog or database to keep track of their data, which then has to be kept in sync with any changes.
With Arraylake, data are organized into repositories (repos). Developers can read and write data to repos using familiar Zarr, NumPy, Dask, and Xarray APIs, but the contents, including all of the rich metadata with their Zarr groups and arrays, are automatically exposed via a user-friendly data catalog. Developers can browse the data catalog from the Arraylake Python client (including some nice Jupyter widgets), CLI, and web app. The ability to quickly discover and share data across a team is a massive productivity boost for developers! Read more about the data catalog in our documentation.
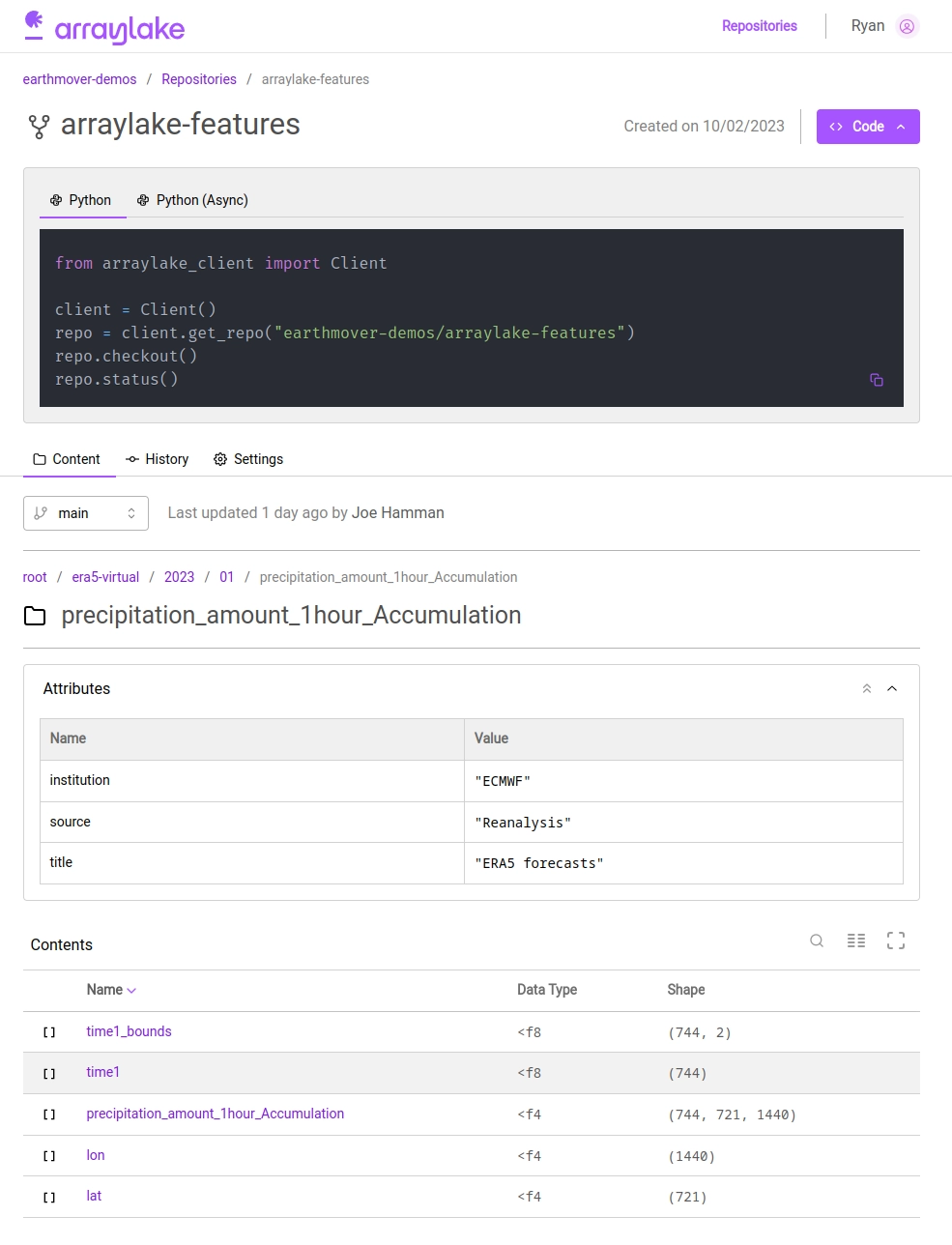
Arraylake web app screenshot
Transactions
Problem: Zarr datasets span multiple files or objects, including both metadata and chunk data. While a Zarr dataset is in the process of being updated (overwitten, appended to, renamed, etc.), users accessing that data may see inconsistent data, leading to errors. Multiple writers might interfere with each other in unpredictable ways if attempting to update the same data. These characteristics are unacceptable in a production system.
Arraylake implements a transaction system to guarantee serializable isolation of updates to your Zarr data. Changes with a transaction are made first in a staging environment. They can be quality controlled and verified by the writer, and, when ready, committed via an atomic commit. This transaction step also allows multiple writers to safely write to the same arrays or groups at the same time using optimistic concurrency, either smoothly merging their changes from all writers or else rejecting all but one commit. These features were inspired by Apache Iceberg and adopted to the Zarr data model.
Data Versioning
Problem: Teams often want to track multiple versions of their data as it evolves over time. With Zarr on object storage today, the best way to do that is by copying the entire dataset to a new location to snapshot it. But when dataset sizes are measured in terabytes and beyond, this approach is slow and wasteful.
With Arraylake, every commit creates a new, immutable snapshot of the state of the data at that time, and subsequent commits only store diffs from the previous snapshot. Applications can check out the repo at a specific commit and will always see the same data. This is crucial, in particular, for building reliable machine learning pipelines on top of evolving real-time datasets. Read more about the version control model in our documentation.
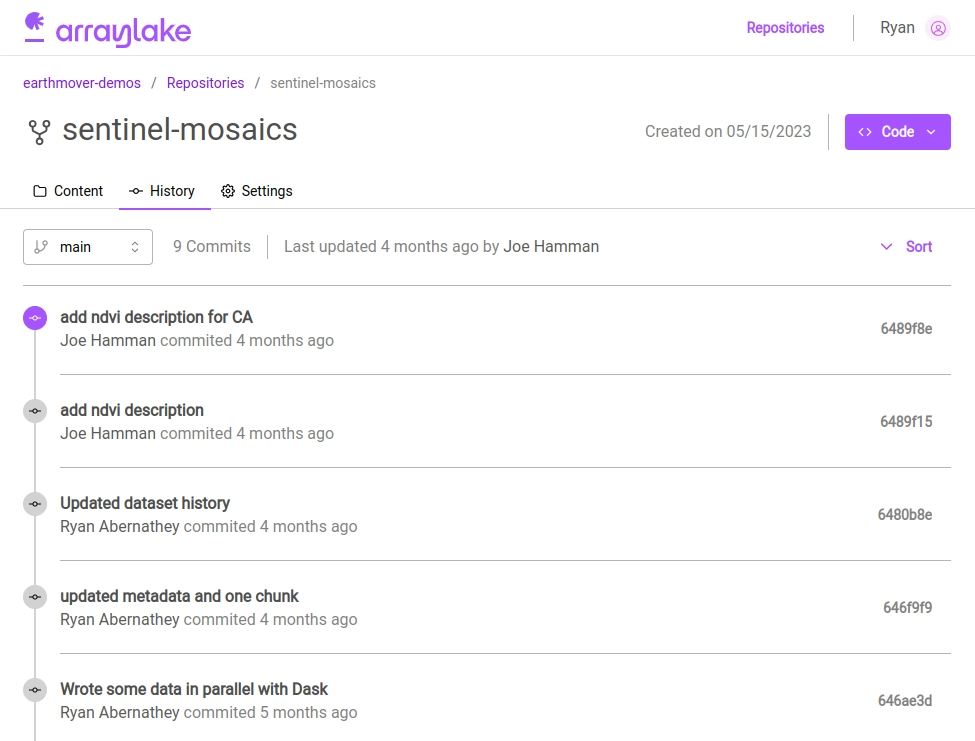
Arraylake web app commit history view
Virtual Files
Problem: Exabytes of array data already exist in non-cloud-optimized formats like HDF5, NetCDF3/4, TIFF, etc. Transforming all these files to Zarr in order to optimize their cloud performance is expensive, impractical, and disrupts data lineage.
Arraylake is able to ingest HDF5, NetCDF3/4, and TIFF files “virtually”, without copying any data, and re-expose it via the high-performance cloud-native Zarr interface. With this feature, developers can stop fussing over file formats and focus more on their high-level data science objectives. Under the hood, Arraylake leverages the amazing Kerchunk library for scanning these files while implementing its own mechanism for tracking the “references” generated by Kerchunk in a database. Read more about Flexible File Format Support in our documentation.
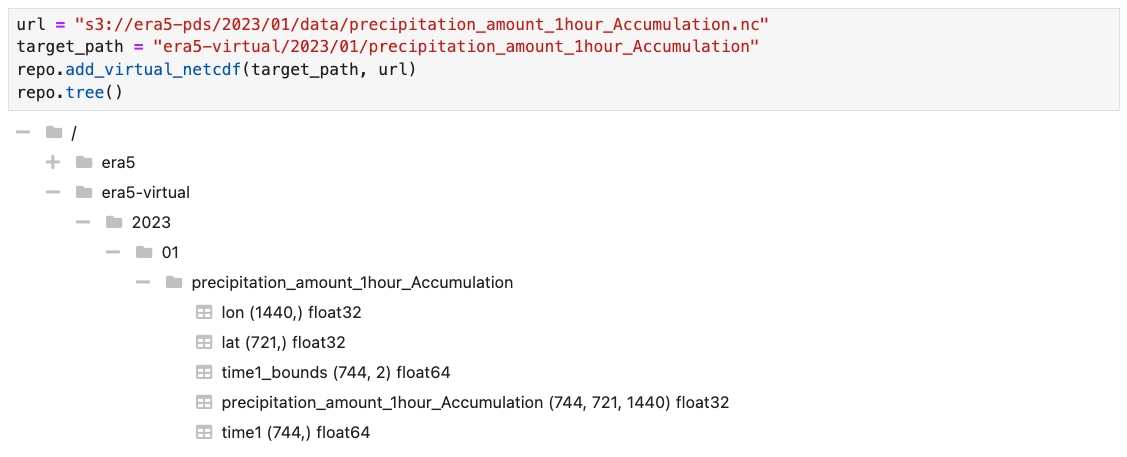
Arraylake virtual file support
Overall, the goal of these improvements is to provide developers with a massive upgrade to their array-based data science workflows in the cloud. As practitioners, now that we’ve gotten used to storing data in Arraylake, we can’t imagine going back to the old way!
Our Private Beta
So far, we’ve been building Arraylake together with a few select design partners. Today, we are launching our private beta availability. That means we are looking for more early adopters to take Arraylake for a test drive as we build towards general availability. We are confident that Arraylake is mature, stable, and performant enough for real-world production workflows and are excited to get our product into more hands. As a partner in our private beta, you’ll get early access to Arraylake, with immediate benefits to you and your team, and a chance to shape our product roadmap to your needs. Following the private beta, we’ll be launching in general availability later in the fall.
Who is a good fit for this program?
- Teams that want to use array-centric software like NumPy, Xarray, Dask, and Zarr as a key part of their stack to build cloud-native systems.
- Teams that are using the cloud for array data, but struggling with organizing and collaborating around data they produce.
- Teams looking for a more robust data management system that supports transactions and versioning for large multi-dimensional arrays.
- Teams struggling to manage high-velocity array data, such as those generated from weather forecasts and satellites.
Such teams can be found at a lot of different places: inside large tech companies, at startups, within government agencies and NGOs, at national labs, or within research labs at universities. However, our emphasis on teams is deliberate. Arraylake is a collaborative tool. You’ll get the most out of our product if you’re using it together with others as part of some kind of team.
To join the wait list for the Arraylake private beta just sign up here, and if you have any questions about Arraylake and Earthmover, feel to drop us an email.
CEO & Co-founder