Cloud native data loaders for machine learning using Zarr and Xarray

CTO & Co-founder
We set up a high-performance PyTorch dataloader using data stored as Zarr in the cloud
Machine learning has become essential in the utilization of weather, climate, and geospatial data. Sophisticated models such as GraphCast, ClimaX, and Clay are emerging within these domains. The advancement of these models is greatly influenced by the widespread availability of cloud computing resources, particularly GPUs, and the abundance of data stored in cloud repositories. Despite these advancements, there remains a lack of established best practices for efficiently managing machine learning training pipelines due to the diverse range of data formats used when storing scientific data. In this blog post, we discuss an architecture that we have found highly effective in seamlessly integrating multidimensional arrays from cloud storage into machine learning frameworks.
The problem
At its core, the problem we’ll be tackling in this post is how to efficiently train machine learning models where the inputs are multiple multi-dimensional arrays (a.k.a. tensors) stored in cloud storage. By efficiently, we mean that we’ll be optimizing for hardware utilization (e.g. GPU) while minimizing complexity and development cost.
As developers of Xarray, Zarr, and more recently Arraylake, we’ve talked to dozens of different teams and observed a wide range of different practices in this area. Most teams begin with raw source data (e.g. from a dataset like ERA5) stored in their cloud data lake in a format like Zarr, NetCDF, or GRIB. From there, the data need to be preprocessed into custom features / samples and loaded into a GPU-based ML model training loop. The training datasets range in size from several GB to hundreds of TB. Our observation is that many of the approaches in use today have required significant engineering effort to develop and / or have pretty serious drawbacks in terms of performance and convenience. Specifically, there are two patterns that we would like to avoid going forward:
- Pre-computing samples and storing a second copy of training data.
This is suboptimal because storing a second copy of the training data is expensive and time consuming – limiting a team’s ability to iterate quickly. - Downloading data before training to a local file system (e.g. SSD).
This is suboptimal because the relatively small SSD size naturally limits the amount of data that can be used during training, in addition to requiring significant up-front GPU idle time.
During a recent collaboration with Zeus AI, we observed them using an approach that utilized a familiar set of tools, including Zarr, Xarray, Dask, Xbatcher, and PyTorch for their ML training workloads. This blog post, which aims to provide a general description of a framework that we think will be a useful pattern for many ML applications, was one of the outcomes of that collaboration.
What we’re showing in this blog post is a simple pattern designed to achieve three main goals:
- Stream Zarr data from cloud storage directly into a model at training time
- Use tools most environmental scientists know (and love), specifically Xarray
- Achieve high throughput during training (key metric: saturate the GPU)
The solution
When we started working on this problem, we were fairly sure we needed to build a custom PyTorch dataloader on top of Zarr. What we found was that existing tools can be stitched together to get a remarkably performant data loader. The basic architecture is outlined below:

- The data is stored as a collection of Zarr arrays. In our demo, these arrays are chunked and compressed using standard parameters (1 to 16mb chunks compressed using Blosc LZ4) and stored on Google Cloud Storage.
- Xarray is used as the primary data model and interface for preprocessing the data (e.g. variable selection and feature engineering logic).
- Xbatcher is used to generate small batches of data to feed into our model. Xbatcher is a small utility library meant to bridge the gap between Xarray and ML frameworks by handling the logic of generating and combining small batches of Xarray datasets.
- Dask is used to load multiple chunks of Zarr data across multiple variables concurrently and to (optionally) cache materialized chunks.
- Finally, PyTorch’s Dataloader API is used to orchestrate data loading across multiple processes. This API also enables shuffling, loading of multiple batches concurrently, and reading multiple batches ahead of time.
Wiring all of these pieces together is actually pretty straightforward. To show how this can be done and to demonstrate how you can get good performance out of such a system, we put together a demo repository on GitHub: earthmover/dataloader-demo. The demo provides a simple CLI that will let you take the data loader for a spin.
To show how this pattern can perform, we conducted two experiments. Both experiments use data from the Weatherbench2 dataset stored in Arraylake, whose native format is Zarr. (It’s also possible to run the example using the Weatherbench data in Google Cloud public data). The Weatherbench2 data is opened using Xarray and a lightweight custom Pytorch Dataset is used to connect Xbatcher to a Pytorch Dataloader. We ran these experiments on a ml.m5.12xlarge AWS SageMaker instance in the US-East-1 region.
The first experiment is meant to demonstrate what the out-of-the box performance looks like without any optimizations (parallel loading, pre-fetching, or caching). Using default settings, the results (Figure 1) don’t look great. Our application ends up spending most of its time producing batches of data (purple), while the training step (red) has lots of gaps (white) between them. On average, our training step has to wait over 1.3s for the next batch.
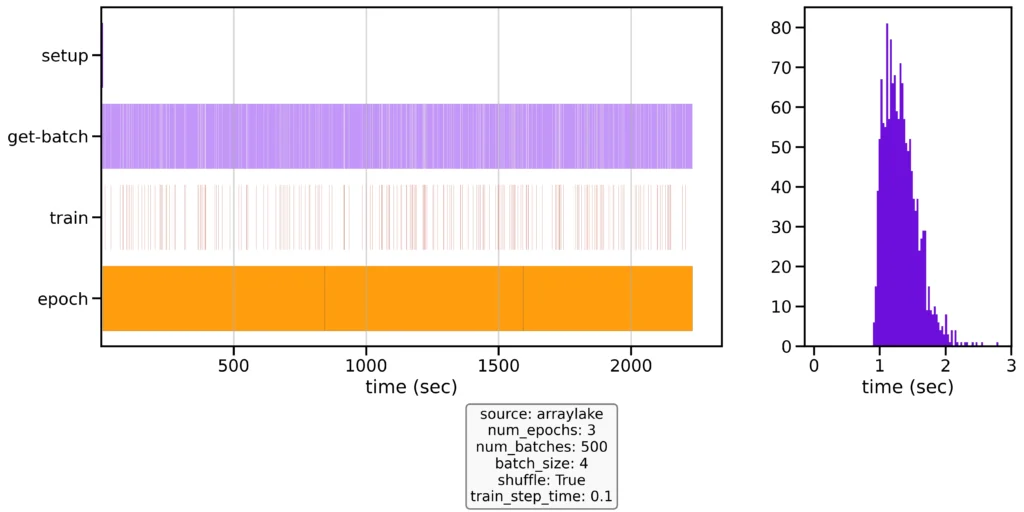
At this point, folks might look at this and say—I need to copy the data to a local SSD to get good throughput. However, with a few tweaks, we can easily speed up the training loop by ~15x.
The second experiment we will show applies a number of optimizations. For this next iteration, we will use Pytorch’s multiprocessing functionality to load batches in parallel and Dask’s threaded scheduler to provide concurrency and caching when loading multiple arrays into memory. Finally, we’ll configure the dataloader to utilize prefetching to make sure the model’s next batch of data is always available by the time a training iteration is complete.
The results (Figure 2) are very encouraging. After a surprisingly lengthy startup period (does anyone know why it takes PyTorch over two minutes to boot up 32 workers?), the training loop is shown to be nearly completely saturated. And we see that data fetching and training are happening concurrently. Most importantly, our three training epochs complete in ~1/15th the time. Whereas our first example waited, on average, for over 1.3s for the next batch to be generated, our second example waited for just 0.007s!
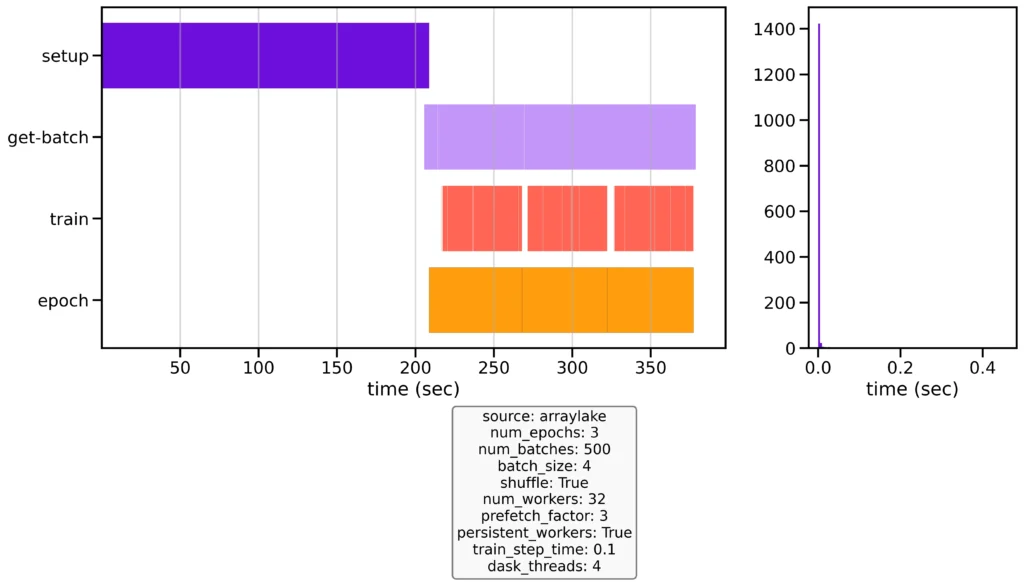
With these optimizations in place, we can see that our training loop is now highly utilized. This is exactly what we want to see!
In the end, our dataloader was configured as follows:
Now you may be wondering how we came up with this set of parameters. So let’s walk through them one by one:
batch_sizeandshufflewere dictated by our sample problem. We wanted each training iteration to include data from four mini-batches and we wanted to shuffle the order that we were pulling samples from our Xbatcher generator.- Dask was configured to use its threaded scheduler and four workers. This was chosen based on the number of tasks needed to materialize a batch that draws from multiple (3) variables concurrently. With this configuration, we could load a single mini-batch in 0.3s.
prefetch_factorwas configured to be the ratio of the time to load a single mini-batch (0.3s) to the time to complete one training step (0.1s).- Finally,
num_workerswas configured to keep pace with the training loop. This can be calculated asprefetch_factor x loading_time / t_train.
Summary
We set up a PyTorch dataloader using data stored as Zarr in the cloud and showed that existing tooling can be easily configured to saturate the training loop in a ML application.
When we first started this work, we thought the outcome might be a new package to help orchestrate this sort of model training application. However, in the end, we decided that the lessons learned were simple enough to just summarize with a simple blog post. We hope you find this useful!
Want to run this demo yourself? Checkout the full demo in the earth-mover/dataloader-demo repository on GitHub.
The two experiments described in this post can be rerun using:
If you are looking for ways to level up your workflows that use Xarray and Zarr in the cloud, it may be time to check out Arraylake - Earthmover’s data lake platform for managing Zarr arrays and metadata in the cloud. Check out our docs or reach out to book a demo if you want to learn more!
Acknowledgements
This work was done in collaboration with Zeus AI, a NASA Ames Research Center spinout developing AI-based weather monitoring and forecasting products.
CTO & Co-founder