Zarr-Python 3 is here!

CTO & Co-founder
Note: This post was originally published on the Zarr developer blog.
After more than a year of development, we’re thrilled to announce the release of Zarr-Python 3! This major release brings full support for the Zarr v3 specification, including the new chunk-sharding extension, major performance enhancements, and a thoroughly modernized codebase. Whether you use Zarr to managing large multi-dimensional datasets in the cloud or for high-performance machine learning applications, we’ve built Zarr-Python 3 to help you. Let’s dive into some of the details of this release!
Zarr-Python 3 is available today on PyPI and Conda-Forge. It is compatible with Python 3.11 and above.
Support for Zarr’s v3 specification
The most notable addition in Zarr-Python 3 is complete support for Zarr’s v3 specification. The v3 specification brought greater multi-language interoperability and new extension points for customizing Zarr (codecs, chunk grids, data types, and stores).
Beyond supporting the core v3 specification, Zarr-Python 3 also includes support for the chunk-sharding extension. This feature allows for multiple chunks to be stored in a single file (or object), allowing users to utilize much smaller chunks without increasing the total number of objects in a dataset. Without chunk sharding, users optimizing for read-heavy applications had a difficult choice: either use a small chunk size, but create a huge number of stored objects, or use a large chunk size, but suffer poor IO for random reads into the data. With chunk-sharding, the number of stored objects is decoupled from the chunk size. Users can safely create very large Zarr arrays with very small chunks without generating a glut of stored objects. For more on how sharding works, see Zarr-Python’s sharding documentation page.
The code block below show’s off Zarr-Python’s new API for creating sharded arrays:
Note that Zarr-Python 3 maintains read and write support for data stored according to Zarr’s v2 specification. Some features (e.g. sharding) are not available for v2 data. Users can set zarr_format=2 in the top level API to continue using Zarr v2’s specification.
Major performance improvements
Zarr-Python 3 delivers significant performance improvements across the board. A large part of the refactor focused on making the core of the library fully asynchronous, using Python’s asyncio library. The new asynchronous core enables efficient I/O operations and better utilization of system resources. This means that multiple I/O operations can be performed concurrently, leading to faster data access and reduced latency, especially when data is stored on high-latency storage backends (like cloud object storage).
For compute bound operations (like compression/decompression), Zarr now dispatches to a managed thread pool. Combined with asynchronous IO, this threaded parallelization allows for Zarr to take full advantage of the compute resources available when reading and writing data.
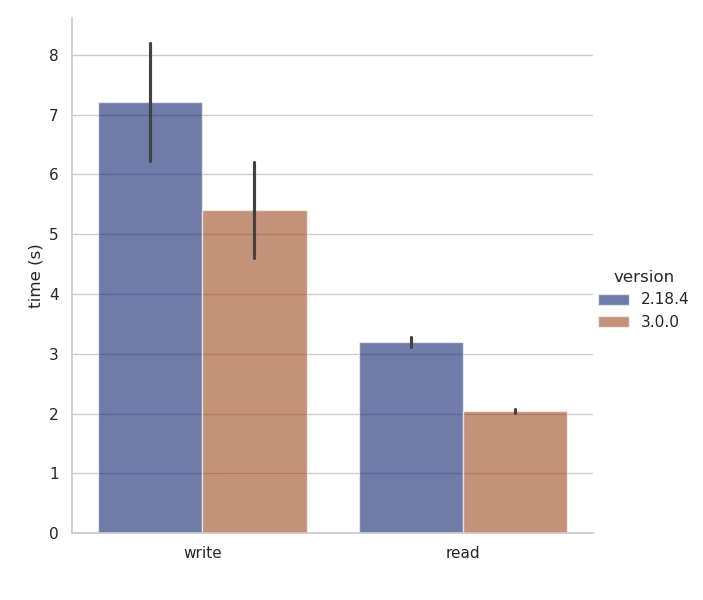
Performance analysis of Zarr-Python 3 relative to Zarr-Python 2.18.4. Test wrote and read a 1GB array (shape=(512, 512, 512), chunks=(512, 512, 8), dtype=‘float64’) to and from AWS S3 from a m6i.4xlarge VM in the same region.
While early benchmark results appear to show very promising performance results relative to prior versions of Zarr-Python, we have yet to do dedicated performance tuning. Users should expect further performance improvements as Zarr-Python 3 matures. In fact, we are already working on identifying and addressing a number of known performance bottlenecks to further enhance the library’s speed and efficiency.
Built with extensions in mind
Zarr-Python 3 is designed to be highly extensible. Key features include:
-
New
StoreABC: A new abstract base class for defining custom storage backends, making it easier to integrate Zarr with various storage systems. This allows for seamless integration with cloud storage solutions, distributed file systems, and other data storage technologies.Zarr-Python 3 includes for the following stores:LocalStore- for reading/writing to a local file systemFsspecStore- for reading/writing to remote/cloud storage (based on fsspec)ZipStore- for reading/writing to a ZipFile (experimental)
Additional stores are also in development (like Earthmover’s Icechunk store).
-
CodecandCodecPipelineEntrypoints: Zarr-Python 3 provides Python entry points for defining custom codecs and codec pipelines, enabling flexible data compression and encoding strategies. This empowers developers to tailor data compression and encoding to specific use cases and optimize storage and performance.Numcodecs has been adapted to use Zarr’sCodecentrypoint system andZarrs-pythonhas already developed an experimental Rust-basedCodecPipeline.
Modernized Codebase
The Zarr-Python 3 codebase has been significantly modernized:
- 100% Type Hint Coverage: Comprehensive type hints improve code readability, maintainability, and IDE support. This makes the code easier to understand, debug, and refactor, leading to higher code quality and reduced development time.
- Cleanly Defined Public/Private API: A clear distinction between public and private APIs enhances code organization and stability. This ensures that the public API remains stable and consistent, while allowing for flexibility and future development in the private API.
- Improved Development Environment, CI/CD, and Testing: A streamlined development workflow, robust CI/CD pipelines, and comprehensive testing ensure high-quality releases. This rigorous development process helps to identify and fix bugs early, leading to more reliable and robust software.
Migration from Zarr-Python 2 to 3
We have done everything possible to make the migration from Zarr-Python 2 to 3 as easy as possible. The 3.0 migration guide provides details the parts of the Zarr-Python API that have changed and provides suggested actions for migration. Additionally, libraries such as Xarray, Dask, have already added support for Zarr-Python 3.
Conclusion
Zarr-Python 3.0.0 marks the beginning of a new chapter for the Zarr-Python project. We encourage you to try out this new version and provide feedback. We’re also excited to see the development of new extensions built on top of this solid foundation, such as Icechunk, Zarrs-Python, and VirtualiZarr.
The development of Zarr-Python 3 was a huge effort, spanning over 12 months and including contributions from over 30 contributors. Special thanks to Davis Bennett and Norman Rzepka who helped me kick off the initial refactor in Potsdam, Germany in December 2023.
Further reading
CTO & Co-founder