From 10 Minutes to 10 Seconds: How Woods Hole Scientists used Icechunk to Optimize Ocean Data Access


Postdoctoral Investigator, WHOI
Note: this is a guest post by Woods Whole Oceanographic Institute scientist Dr. Iury Simoes-Sousa
Among the many ways the ocean affects our lives, one of the most fundamental is through its ability to transport key climate variables such as heat, nutrients, and marine organisms. This transport happens across scales, from vast currents like the Gulf Stream to smaller features where currents break into vortices (eddies) that trap and carry water and its properties.
Most studies of oceanic vortices have relied on satellite data. However, these vortices are not all alike. Their vertical structure varies, and that variation governs how they redistribute the different ocean properties. This is the primary reason why creating a dataset that links satellite-identified vortices to in-situ profiles is important for the community.
During my PhD, I developed a dataset that combines satellite-identified vortices with oceanographic profiles from the World Ocean Database (WOD). These vertical profiles include cruise data, observations from autonomous vehicles such as Argo floats, and even sensors mounted on marine mammals. This dataset allows oceanographers to analyze the three-dimensional structure of vortices, which is essential for understanding their role in the climate system.
The context was simple: I needed such a dataset for another project, and at the time, no ready-to-use resource existed for studying the vertical structure of ocean vortices. Being in a computational science program, I saw an opportunity to build something not only for myself but also for the broader scientific community. The full dataset is described in our article published in Earth System Science Data (Copernicus). Here, I’ll walk through the core ideas.
Reshaping WOD Data
The first challenge was to reformat WOD profiles. WOD data are stored as ragged arrays: all observations of a given property, from multiple profiles and instruments, are stored in a single vector. While this saves space, it makes analysis cumbersome.
We reorganized the data dimensions from (observations) to (casts, levels), where casts are unique profile IDs and levels are vertical sampling depths. Pressure values are stored as a variable, since vertical resolution depends on the instrument and mission goals. This format makes it easy to select profiles by ID and perform vertical derivatives or integrals of ocean properties. Thanks to intelligent compression, the Zarr version of this dataset was still much smaller on disk than the original one.

Figure 1: Rearranging WOD profiles before combining them with satellite-identified vortices.
Matching Profiles to Vortices
Once reformatted, we matched millions of profiles to their position relative to satellite-detected vortices. Profiles inside vortices were tagged with vortex properties (radius, amplitude, etc.) and IDs; we call these matched profiles. Profiles outside vortices form the background set.
The matching was run in parallel on an HPC system using xarray and dask, chunked by month of observation.
The Bottleneck of OPeNDAP Access
Our initial plan was to publish the data as netCDF4 files served over OPeNDAP, separated by property (temperature, chlorophyll, etc.), data source (Argo, marine mammals, etc.), and domain (matched or background). OPeNDAP provides lazy access through tools like xarray, allowing users to inspect metadata or request subsets on the fly.
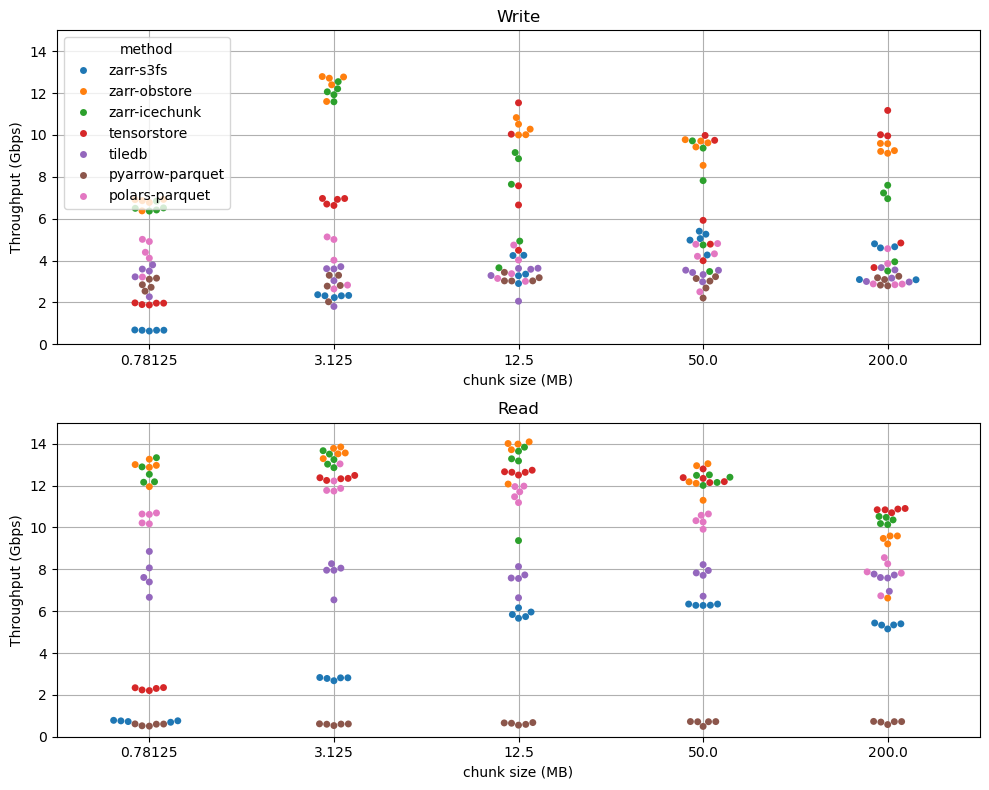
In theory, this should have worked fine. But during peer review, I tested an example and realized access was painfully slow. For instance, the Argo temperature file (about 7.2 GB) took 10 minutes to subset only 1,063 casts from a single vortex:

Converting to Icechunk
To test performance, I converted each netCDF4 file into an Icechunk repository stored on AWS S3, with chunks of 1,000 casts. I had no prior experience with Icechunk, but the process was straightforward (check the code on this link). Accessing the same subset through Icechunk reduced the runtime from 10 minutes to just 10 seconds:

The same operation that took nearly 10 minutes now finishes in seconds. Icechunk not only speeds up access but also enables versioning, a feature that will be invaluable as these datasets continue to grow and evolve.
Eddy trajectory and anomalies
If you want to see how we query and analyze this data to construct temperature and salinity anomalies like the one below, check out this notebook.

Figure 2: (a) Eddy trajectory (teal line) and locations of associated vertical profiles (gray dots). The inset map shows the eddy region in the western North Pacific, near Japan (Kuroshio Current). (b) Composite section of conservative temperature anomaly (°C) as a function of distance from the eddy center, normalized by the speed radius. (c) Corresponding composite section of absolute salinity anomaly (g/kg). Positive values indicate warmer and saltier water, and negative values indicate cooler and fresher water relative to the regional background (World Ocean Atlas 2018).
Making an analysis like this is powerful because it captures an eddy, a living, moving structure, as a coherent feature that can be studied statistically. Each gray dot represents a vertical profile that sampled a small part of the ocean at a different time and location within the eddy’s boundaries. By compositing them relative to the eddy’s center and trajectory, a cloud of scattered observations becomes a clear physical picture: a rotating lens of warm, salty water surrounded by cooler, fresher layers. This approach reveals how dynamic features, such as ocean vortices, influence the transport of climate-relevant properties, like temperature and salinity, over hundreds of kilometers and through months of evolution.
Summary
Previously, we relied on NetCDF, OPeNDAP, and on-prem servers for sharing data. By adopting Icechunk and serving our data in the cloud, we were able to simplify our own data sharing infrastructure while also massively speeding up access for users. We are planning to expand our usage of Icechunk to cover much larger datasets in the near future.
Postdoctoral Investigator, WHOI