Solving NASA's Cloud Data Dilemma: How Icechunk Revolutionizes Earth Data Access

CEO & Co-founder
Summary
NASA has been migrating over 100 petabytes of data from on prem systems to the cloud for the last several years and is now able to focus on measures of efficiency that were not possible before. Earthmover and Development Seed worked with NASA to pilot Earthmover’s open-source Icechunk tensor storage engine to optimize cloud-native data access for level 3 datasets on top of existing archival files without a costly and complex data migration. When applied to the popular GPM IMERG precipitation dataset, this technology enabled a 100x speedup for extracting time series data compared to existing approaches for the same task, while also simplifying the end-user experience.
Opportunity: Existing archival data formats are not designed for high-performance access in cloud object storage
NASA is the world’s leading Earth-observing organization, operating dozens of science missions involving state-of-the art satellites. These missions produce a continuous and ever-increasing stream of complex scientific data. These data underlie a vast range of critical applications, from weather forecasting to monitoring deforestation. To address the technical demands posed by this data stream in a scalable and cost-effective way, NASA’s Earth Science Data Systems (ESDS) Program uses a commercial cloud environment (AWS) for its data infrastructure. This ongoing migration from NASA’s on-prem systems involves transferring data, systems, and services to the Earthdata Cloud environment. The volume of data stored in NASA’s AWS S3 buckets is expected to surpass 320 Petabytes by 2030. The vast majority of this is multidimensional scientific data stored in archival formats like NetCDF and HDF and meets many data users where they are already.
However, NetCDF and HDF were originally designed to be accessed from traditional POSIX file storage, not cloud object storage. This leads to performance limitations for cloud-native applications and data science workflows which rely on these formats.
To illustrate the consequences of these limitations, consider a common example where a data user wants to extract a time series of precipitation of a specific location on Earth. NASA’s Goddard Earth Sciences Data and Information Services Center (GES DISC) uses a blend of satellites to make a global estimate of precipitation every half hour: the GPM IMERG dataset. Each precipitation snapshot is distributed as a single global NetCDF file. That’s as many as 1488 files per month.
Snapshot of GPM IMERG precipitation data.
NASA maintains an application called Giovanni which enables users to extract and visualize a time series of many different datasets, including GPM IMERG. Users can click a point on a map, click a button, and out pops a time series plot. Currently Giovanni runs in an on-prem data center, where the GPM IMERG files are accessible on a shared POSIX filesystem, not in the cloud.
How could a cloud-based application perform the same task against data stored in object storage? If the application has to download all 1488 files to a local disk before responding to the request, this introduces a large performance penalty. Alternatively, the data could be transformed to a cloud-native format such as Zarr, which can be read efficiently from cloud object storage. While this would improve performance, it would be an enormous undertaking at the hundred-Petabyte scale. Finally, the application could use Elastic Block Storage (EBS) rather than S3 to store the data. This “lift and shift” would allow the on-prem application to be migrated with minimal changes to code and architecture. However, EBS is at least 20x more expensive than S3, and is also much more complex to configure and maintain.
Solution: Icechunk and Virtual Zarr Stores
NASA partnered with Earthmover and Development Seed to pilot an approach to address this problem based on Earthmover’s open-source Icechunk tensor storage engine. By applying Icechunk, we were able to enable high-performance cloud-native access to the GPM IMERG dataset stored in S3 without transforming the data to a new format. Instead, we leveraged Icechunk’s virtualization capabilities to present the entire collection of over a million files as a single analysis-ready Zarr data cube.
We used VirtualiZarr to scan the files, producing an index describing the precise location of every chunk of data within each file. We then stored these “chunk manifests” in Icechunk’s optimized format. Once this index is built, applications such as Giovanni can quickly access the exact pieces of data they need across the entire set of files, bypassing the need to download entire files. Users can also interact directly with the Icechunk data, fetching data directly from object storage and feeding it into analysis workflows and ML pipelines. Icechunk’s optimized Rust-based I/O engine enables thousands of data requests to be issued in parallel in just seconds, efficiently extracting just the needed data from the underlying NetCDF files.
In the benchmark shown below, we were able to extract a month-long time series from GPM IMERG data stored in S3 in just 3 seconds. In comparison, the previous cloud-based approach takes 5 minutes! Meanwhile, the on-prem Giovanni application takes 45 seconds for this same operation accessing the same files on POSIX storage.
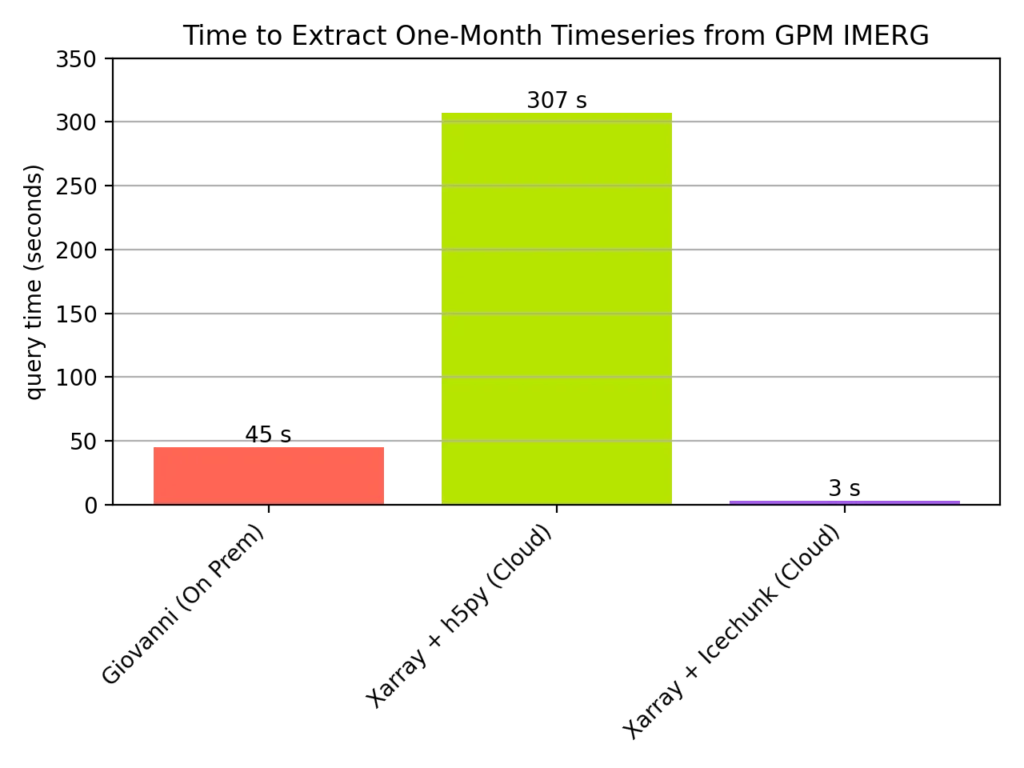
Comparison of different approaches for extracting a one-month precipitation timeseries from GPM IMERG original NetCDF granules (1488 in total). The red bar show the on-premises Giovanni application, running in a cluster with a shared POSIX filesystem. The green bar shows a simple cloud-based approach using Xarray’s open_mfdataset function together with h5py and s3fs to open the files directly from object storage. Finally, the Icechunk approach is shown in purple.Check out the GitHub repo for the full code used to produce and benchmark the Icechunk dataset. (Note, this data is only directly accessible from within a NASA cloud environment, such as VEDA.)
The implications of this approach are dramatic and far-reaching when scaled to a 300 PB data archive. Storing 300 PB of data in S3 is not cheap; the sticker price is over $75M a year. Duplicating archival files formats into a cloud-native format to enable more efficient access would effectively double the storage cost, not to mention the massive compute bill required to perform such a transformation. Alternatively, putting the data on EBS instead of S3 would cost over a billion dollars a year! Compared to these options, the Icechunk approach can deliver tens of millions of dollars of savings storage costs alone, while also reducing operational complexity and enhancing data scientists’ user experience.
What’s Next?
Earthmover’s mission is to empower people to use scientific data to solve humanity’s greatest challenges. We can think of no better way to advance this mission than by working with world leading institutions such as NASA towards the goal of making scientific data more accessible, performant, and useful. This pilot project, conducted over the past three months, has delivered a proof-of-concept which exceeded even our most optimistic hopes. We’re excited to continue and expand this partnership to advance the core Icechunk technology and apply it to more datasets within NASA. If successful, this is one more step in optimizing freely accessible NASA data for anyone to use.
CEO & Co-founder