

Why we started Earthmover
Earthmover is an early-stage startup building a platform for scientific data analytics in the cloud.
Earthmover, an early-stage startup, is building a platform for scientific data analytics in the cloud. Our mission is to empower our customers to use scientific data to address our planet’s most urgent challenges.
It started in the dark days of 2020. My life, like millions of others around the world, was suddenly and severely disrupted by the lockdowns. I was uncertain about the future and scared for my family. But I also experienced a euphoric sense of liberation: big changes are possible, and in fact may be just around the corner. We can break our patterns.
Like many other climate scientists, I also pondered the parallels between COVID and climate change: a dire global problem, illuminated by science, twisted by politics, and ultimately solvable through a mix of ambitious engineering and policy. I was deeply inspired by the heroic work of the scientists who raced to develop COVID vaccines. I realized I wanted to be part of something like that…for climate change.
At the same time, I was watching the continued rapid growth and adoption of the technology we have developed in the Pangeo project. What started in 2017 as a grassroots collaboration between scientists and software developers is now a global community with over 1000 participants. The open-source tools we work on–Zarr, Xarray, and Dask–are now in production at places like NASA, Microsoft, Google, and McKinsey. While I love my oceanography research, I realized that my software side thing had become my main thing.
The idea for Earthmover was born: a new “modern data stack” that would make working with huge scientific datasets (like those found in climate) a breeze.
Joe Hamman–a long-time friend and Pangeo collaborator who has already had a huge impact as a founder of CarbonPlan–was having similar thoughts of his own. The pieces started to fit into place. He was a perfect co-founder.
Building on the success of Pangeo
Pangeo has transformed the way scientists interact with data by providing a way to efficiently store, analyze, and visualize large scientific datasets in a completely cloud-native way. In our opinion, the key to the success of this architecture has been the presence of a central data model: multidimensional arrays with labels and metadata. This data model is embodied by the Xarray Python package, which provides the ability to work with multidimensional array data with the same concise syntax and convenience that Pandas provides for tabular data. (Joe and I are both core developers of Xarray.)
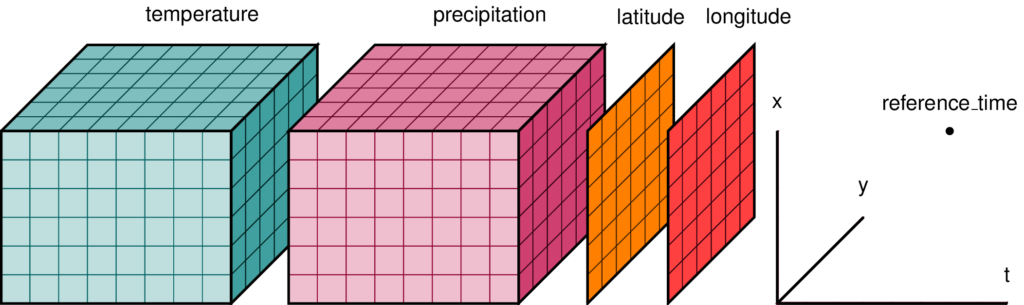
Xarray Data Model, via xarray.dev.
Xarray is a godsend for the many scientists whose datasets cannot be squeezed into the tabular data model of rows and columns.
Andrew’s data (from the NCAR CESM Large Ensemble) consist of hundreds of TB of interrelated five-dimensional hypercubes!
While these tools help a lot, the data infrastructure problem is far from solved. Over the past months, Joe and I have talked to dozens of teams working with geospatial, weather, and climate data, from startups to blue chip consulting firms. We have learned just how much climate tech companies are struggling with data engineering challenges.
Managing stores of scientific data in the cloud is clearly consuming way too much engineering time and energy, preventing companies from focusing on their core mission (like making better climate forecasts using AI).
A cloud-native data stack for science
Earthmover solves this problem by shamelessly copying an already successful business model: the famous Modern Data Stack (MDS; think Snowflake + FiveTran + DBT). The MDS enumerates the sort of managed cloud services that companies find useful enough to pay for in the business data world: data lakes / warehouses, ETL pipelines, data transformations, dashboards, etc. Why don’t Climate Tech and similar companies just use the MDS directly, you may ask? Well, the MDS understands one data model–tables–and categorizes everything else as “unstructured data.” But the scientific data we work with are not unstructured; they just conform to a different data model: labeled multidimensional arrays with metadata. (Beyond climate and geospatial, this data model is used heavily in many other fields–from bioinformatics to finance–and is closely related to the “tensors” of deep learning.)
With Earthmover, a data analyst will be able to quickly calculate temporal trends on massive archives of climate data without having to first build up their own custom data platform.
We decided the best way to meet this opportunity was to create a VC-backed startup. The reason is simple: speed and scale. No other funding model allows us to move with the urgency demanded by the climate crisis. We are mindful of the mixed incentives that can emerge when venture capital and open source mix. Fortunately, we have found a great partner for our pre-seed round with Tony Liu of Costanoa VC, which is why they’ve led our $1.7M pre-seed round. Tony has thought hard about how to build strong open-source-based data companies. Our commitment to multi-stakeholder open source and community-governed open standards (like Zarr and STAC) will allow our products to interoperate with and complement the thriving open-source and open-data ecosystems in a healthy way.
Now is when the real fun begins: We’re building our first product. We hope you will join our mailing list if you’re interested in following our journey. And we’re hiring!