Learning about Icechunk consistency with a clichéd but instructive example

Staff Engineer
In this post we’ll show what can happen when more than one process write to the same Icechunk repository concurrently, and how Icechunk uses transactions and conflict resolution to guarantee consistency.
For this, we’ll use a commonplace example: bank account transfers. This is not a problem you would think is well suited for a multidimensional tensor store like Icechunk. Where are the arrays? Where is the big data? However, it’s a simple example, one you have probably seen before if you have done any concurrent programming, and it highlights the most important components of transactions and conflicts.
Let’s get to it!
The model
We want to model a series of concurrent money transfers between a set of bank accounts.
Icechunk is a Zarr store, so, we’ll need to fit this problem into the Zarr data model.
- We need a Bank with all its accounts. We’ll use an Icechunk repository for that.
- To represent the accounts we’ll have an
accountsarray in the root group of the Zarr hierarchy. - Account numbers will be integers: 0, 1, …
- We’ll store the balance for account
iat indexiof theaccountsarray. - So,
accountswill be a 1-D array ofuint64representing the balance in cents of each account.
Initialization
Let’s first set up the repository and array.
The whole code for this post can be found in the Icechunk repository if you want to play with it. We’ll copy the important excerpts here.
We need to create an Icechunk repository. We’ll create one on a local instance of MinIO, but you can use S3, GCS, R2, Tigris or any other object store supported by Icechunk.
As you can see, after creating the repository we start a session and create the accounts array. It has one element per account (line 18) and one account per chunk (line 19). Yes, this is not a “normal” Zarr use-case, those are tiny 8 byte chunks. In fact they are so tiny that Icechunk will, by default, optimize them away inlining them into the manifests. But it doesn’t matter, things would be the same with chunks of any size.
We commit the session after creating the array. No values have been written to the array yet, so if we were to read it, all elements would come back as fill_value=0.
Next, we need to initialize the accounts balances. In a very unrealistic way, we’ll render initial balances from a uniform distribution.
Pretty standard Zarr and Icechunk stuff. We start a writable session (line 2), we find the array (line 4), we initialize the element that corresponds to each account (line 9), and finally we commit (line 12).
The function returns the total balance across all accounts. We are going to simulate transfers between all these accounts; at the end of the simulation, the total amount of money in the system must be unchanged, no money lost or created, only transferred within the system.
Executing concurrent transfers
Let’s now write the main driver loop. We want concurrent, random transfers between random accounts. We will use a ProcessPoolExecutor with 10 workers for the concurrency, but using threads, or multiple machines would work in the same way.
Let’s break down the code a bit.
In lines 1-4 we define an enum, to represent the result of a single transfer operation.
The concurrent_transfers function takes the number of accounts in the system, and how many transfers we want to execute. We also pass a transfer_task argument that will be in charge of executing each transfer. We will inject different functions into this argument to get different behaviors. The repo argument is assumed to be initialized already.
In line 15 we use the Executor to launch the tasks, with a concurrency of 10, other numbers would work similarly.
After all tasks are done, we need to verify the results. The most important of these checks is on line 26. We make sure the total amount of money in the system hasn’t changed. Transfers, even if concurrent, should preserve the total amount of money. For this check we use the little helper function:
Which adds the total money, while at the same time verifying there are no negative balances, since we won’t allow that.
The remaining work is to define the transfer_task function. Let’s start with something basic:
transfer simply checks the account balance and, if possible, moves the money from one account to the other. If balance is not enough it returns WireResult.NOT_ENOUGH_BALANCE.
unsafe_transfer_task has a bit more work to do. It selects random accounts and amounts and calls transfer to do the actual work. Finally if the balance was sufficient, it commits the repository with the change.
As you can see, the transfers are independent operations. Each transfer starts a new Icechunk session, changes the accounts array and finally commits the repo to impact the change to persistent storage. We are simulating independent processes, without any type of coordination, leaving all the hard work of ensuring consistency to Icechunk.
Icechunk is consistent by default
Let’s run the code now. We just need a main function that calls the different pieces we have:
We create initial balances for 50 accounts, and run 100 random transfers with a concurrency of 10. This is what we see when we run the code:
icechunk.session.ConflictError:
Failed to commit,
expected parent: Some("4VB7YGVR85E9A2GY1ZV0"),
actual parent: Some("W0T7M6GAFAPA8WYEVWP0")What happened here?
Our code has a serious consistency issue, Icechunk is trying to save our data by throwing an exception instead of accepting a dangerous change. Each transfer is using an isolated Icechunk transaction, but even if Icechunk transactions are atomic and isolated, problems can still happen.
The issue with the basic approach
Our concurrent transfers simulation system will “leak” money. The operation that checks the balance on an account, can interleave in a bad way with some other operation that is wiring out money from the same account. If this happens an account can wire more money than its balance, and still end up positive. Here is an example flow showing this condition:
- Account Acc1 has balance: $600
- Process A starts wiring $500 from Acc1 to Acc2
- Process B starts wiring $200 from Acc1 to Acc3
- Process A verifies sufficient balance: 500 < 600
- Process B verifies sufficient balance: 200 < 600
- Process A executes the transfer setting Acc1 balance to $100
- Process B executes the transfer setting Acc1 balance to $400 (because it doesn’t know he balance has been concurrently modified by process A)
- Bad end result: money was created
How can Icechunk protect from this scenario?
Icechunk won’t allow a session to commit to a branch if the the tip of that branch has changed since the session started.
Let’s break that down. When a writable session starts, Icechunks saves the id of the latest snapshot in the branch. When it is time to commit, Icechunks atomically inserts the new snapshot into the branch, but only if the tip of the branch still points to the same snapshot it stored. If a commit was done by some other process/thread before the session was committed, Icechunk will throw a ConflictError exception.
This is exactly why our code is failing. We have multiple concurrent tasks starting a transaction on the same branch, one of them will manage to commit, but all the rest will fail.
This Icechunk behavior is, of course, by design. This is why we want transactions in Icechunk, to protect us from concurrency bugs. Icechunk, before letting a user commit a change, wants proof that they know about the latest writes to the repository branch. In this situation, this behavior saved us from leaking money from the system.
A second approach
There is a simple recipe to deal with the issue above. When transactions fail, we can just retry them. This retry will re-read the modified balance of the account and try to commit again.
Icechunk will take care of ensuring consistency, by rejecting transactions that started before another change was done.
Of all the transactions being attempted concurrently, one will succeed, the rest will fail and will be retried, potentially multiple times. Retrying those transactions, new sessions will be started, and those will have a new chance to commit.
Eventually the system will converge and all transfers will succeed.
After deciding on the random accounts and amount, we start the retry loop. In the loop we execute the transfers while catching Icechunk’s ConflictError exception. When the error happens, we just retry the transaction.
This works and it’s simple. The program completes, and all the validations we included in concurrent_transfers pass. No money was created or evaporated. It has only one problem, as you can guess by the name of the function. It’s slow.
Each transfer takes around a second —see the sleep statement we introduced in the transfer function. We have 100 transfers, and 10 concurrent executors. We would expect this program to run in around 10 seconds plus some. But it takes more than a minute to complete.
Why? It’s incredibly inefficient. We are doing concurrent transfers, but our algorithm is serializing them, only one will succeed at the time. Before a transaction commits it will have to be retried multiple times. When they fail, they have to start over. We wanted concurrency, we didn’t get it. Icechunk helped us ensure consistency, but the performance price was too high.
A fast approach
Does it need to be this slow?
Icechunk is taking a pessimistic approach to guarantee consistency. It’s saying: any two concurrent transactions that are writing on top of the same branch tip are in conflict, only one of them can commit. Then our loop is simply retrying the failed transactions.
This assumption of conflict is not entirely true, but it’s the only safe assumption Icechunk can do by default. Most concurrent transactions will modify different accounts, and then, in our model, they are not in actual conflict. In that situation, it would be perfectly valid to let them both commit. We only need to reject commits if the competing transactions are modifying the same account. The same account means the same array index, which is to say, the same array chunk (because we, intentionally, selected chunk size 1).
Of course, Icechunk has no way to know this “conflict” is not really a conflict. Icechunk doesn’t know what we are storing in the array, or how the values in them are calculated. This is why it needs to take a pessimistic approach, to protect data consistency.
Using rebase
But Icechunk can help us in this case too. Sessions have a rebase method that acts similar to git rebase. Imagine there are two sessions, Session 1 and Session 2, trying to commit on top of the main branch.
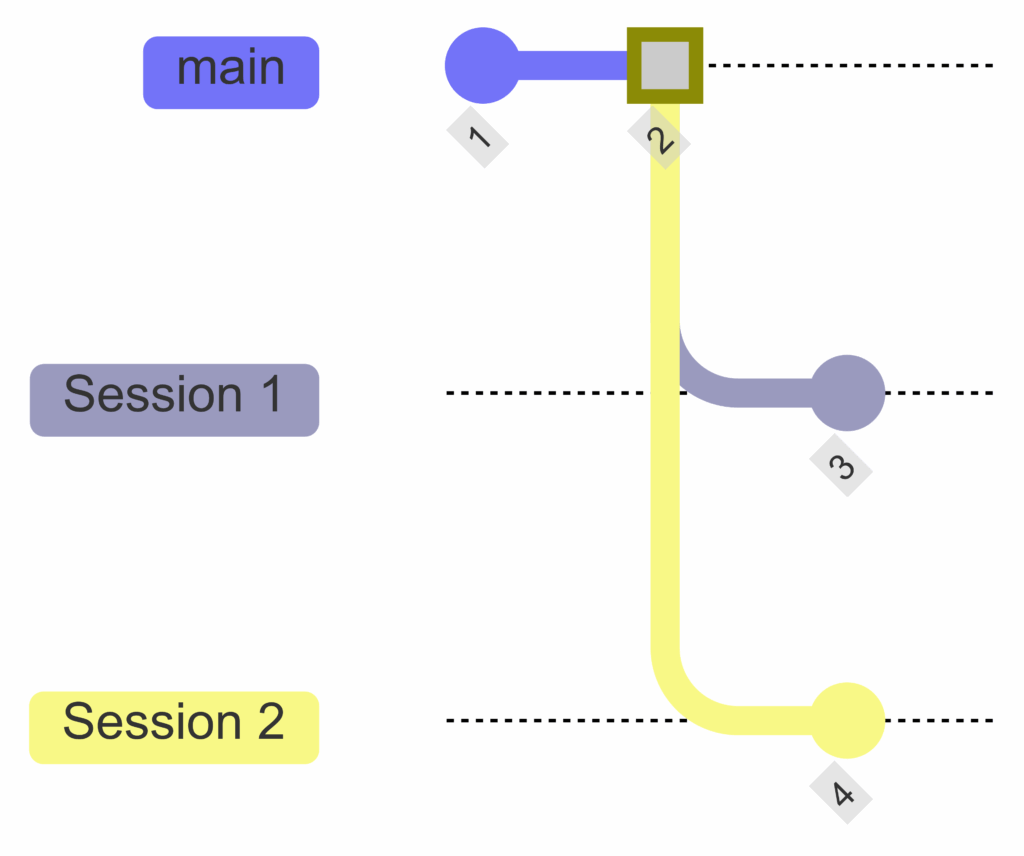
A sample repository before rebasing
The result after committing Session 1, rebasing Session 2 and finally committing Session 2 again would be

The same repository after rebasing Session 2
Just like in Git, a rebase operation can have conflicts too. In our example, rebasing would only be valid if Session 1 and Session 2 modified different accounts. If that’s not the case, we really need to re-run the full session, because we need to read again the new balance for the account that could have been modified by Session 1.
How to solve the rebase conflicts? What happens, in our case, if both Session 1 and Session 2 wrote to the same accounts?
Icechunk has a pluggable conflict solver for rebase:
In this post we’ll only look at the most basic solver, ConflictDetector, but there are others, and more to come soon to Icechunk.
This basic solver will fail to rebase, among other more serious situations, when two sessions wrote to the same array chunk.
This is perfect for our case: if two transactions wrote to the same account (same chunk), we want the rebase to fail. If the two sessions wrote to different accounts, it’s perfectly fine to rebase one on top of the other, in any order. Exactly the semantics we want.
As we mentioned, when we rebase we don’t need to execute the full session again, only the commit operation. This makes a significant difference in the time and, potentially, cost of the write operation.
Merging with rebase
rebase can be called explicitly on Sessions as we mentioned, but there is an easier way. commit method accepts a rebase_with argument that is a ConflictSolver. If commit finds that a different session has successfully committed since the current session started, it will try to use the solver to rebase.
Now we are ready to write rebase_transfer_task:
After the usual finding of random accounts and amount, we go into the same loop we had before. This loop will retry transfers if some other session wrote to the same account. But inside the loop, instead of just committing, we now try to rebase when the commit fails, by using our rebase_with argument.
Why we still need a loop? Remember that rebase can still fail. There will be cases when two concurrent sessions are trying to modify the same account. In this rare cases, we still need to fully retry one of the sessions, to give it opportunity to re-evaluate the new balance. It is just that now these retries will be much less frequent, they will only happen when changes are concurrently done to the same account.
This code is perfectly safe, passes all our validations, and runs in under 15 seconds, instead of more than one minute like the code without rebase. In a real-world situation the difference will be much more significant.
Garbage collection
The mechanism Icechunk uses to offer consistency guarantees is usually called Optimistic Concurrency Control. In particular, Multiversion Concurrency Control (MVCC). It’s a good approach for situations where it’s expected that most transactions will not conflict, and when we want to enable readers an writers to act without locking each other. This is the case Icechunk optimizes for.
To make MVCC work, Icechunk optimistically writes data to object store without taking any locks. When conflicts actually happen at commit time, some extra copies may have been generated in the object store. These files will not be used by any snapshots and they can be safely deleted from the object store.
Icechunk knows how to do this cleanup. We recommend people maintain their object stores clean by running the process we call “garbage collection” every few weeks or months.
We can add at the end of our concurrent_transfers function the following:
The result is something like this printed to the console:
GCSummary(
bytes_deleted=29152,
chunks_deleted=0,
manifests_deleted=21,
snapshots_deleted=21,
attributes_deleted=0,
transaction_logs_deleted=21
)After running this line, the object store is clean, and contains only the objects Icechunk actually needs to represent all versions of the repository.
For the curious, chunks_deleted=0 because we used tiny chunks. As we mentioned, those chunks are inlined into the manifest and never written as separate objects.
If you want to read or play with the full code for this blog post, you can find it in the Icechunk Github repository. Feel free to ask any questions using Github issues, discussions, or our Slack community channel.
Summary
We built a toy example to showcase Icechunk transactions and conflict detection. You would never use Icechunk for this use case in the real world, but it’s a simple and familiar problem that highlights the core concepts in transaction management.
We saw how Icechunk protects its data from concurrency bugs, with a policy that, by default, denies commits when two concurrent sessions are trying to write to the same branch tip.
We implemented a slow but very safe solution, just by retrying transactions.
Finally, to improve performance, we understood and leveraged Icechunk’s conflict detection mechanisms. We used Session.rebase method to merge concurrent sessions if and only if they modify different chunks of our array.
For real-world Icechunk workloads, transactions are usually much longer lived, latencies are much larger, and data is orders of magnitude bigger. But the same principles apply. The MVCC algorithm is a perfect fit for these use cases, and the idea of rebasing sessions is even more useful.
Ultimately, the code for real-world pipelines, is not too different from the basic structure we display here.
Staff Engineer





