Announcing Icechunk!


CEO & Co-founder
TLDR
We are excited to announce the release of the Icechunk storage engine, a new open-source library and specification for the storage of multidimensional array (a.k.a. tensor) data in cloud object storage. Icechunk works together with Zarr, augmenting the Zarr core data model with features that enhance performance, collaboration, and safety in a multi-user cloud-computing context. With the release of Icechunk, powerful capabilities such as isolated transactions and time travel, which were previously only available to Earthmover customers via our Arraylake platform, are now free and open source. Head over to icechunk.io to get started!
This is a blog version of a webinar that took place on October 22, 2024. View the presentation slide deck or check out the video of that webinar:
The Problem
Historically, datasets in Weather, Climate, and Geospatial domains have been distributed as collections of files—in many cases, thousands or even millions of individual files—in archival formats like HDF5, NetCDF, GRIB, and TIFF. This way of distributing data places an enormous burden on end-users to download, organize, and transform the files before they can begin to pursue advanced data analytics or machine learning workflows. Integrated across the entire community of environmental data users, this constitutes a massive drag on humanity’s collective progress towards a more sustainable, data-driven future. Simply lifting and shifting these files to the cloud makes the files a bit easier to download but otherwise does little to ease the burden. (For an example, check out the NOAA GOES Dataset in the AWS Open Data program.)
As core developers of the popular open-source Python libraries Xarray and Zarr, we’ve had a front-row seat to the rapid adoption of cloud technology in the Weather, Climate, and Geospatial domains. We’ve seen the evolution from tools and formats mostly geared to an HPC environment (FORTRAN, HDF5, MPI, etc.) to the modern “cloud-native geospatial” landscape (Python, Xarray, Dask, Zarr, Cloud-optimized GeoTiff, GeoParquet, DuckDB, etc.). Earthmover founders Ryan and Joe implemented the original integration between Xarray and Zarr that allowed our community to start transforming archival file formats to Analysis-Ready, Cloud-Optimized (ARCO) datasets. The ARCO paradigm goes beyond simply adopting new file formats—it means rethinking the centrality of files themselves in workflows. ARCO datasets effectively hide the underlying physical storage of the data and expose a user-friendly spatiotemporal data cube capable of supporting different analysis workflows and query patterns.
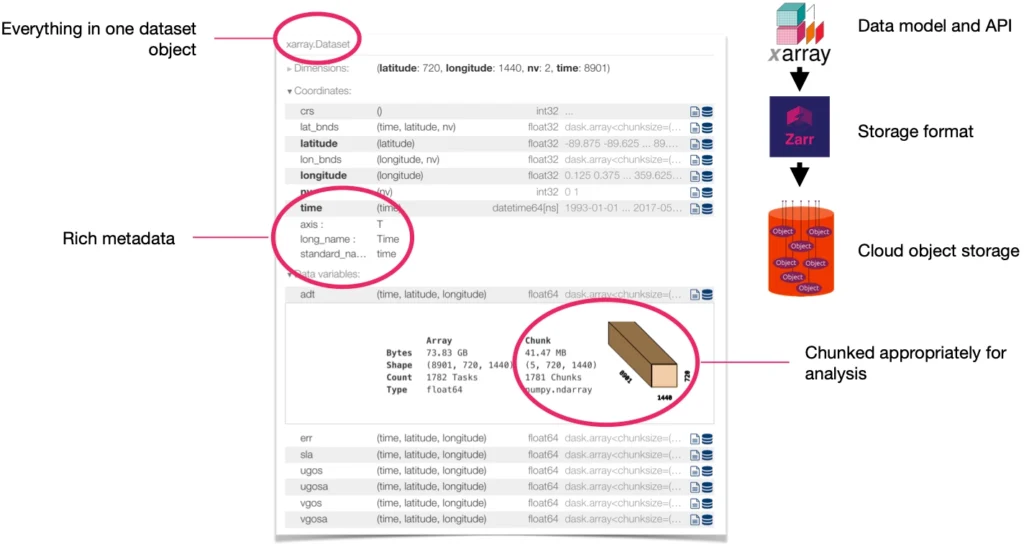
Example of Analysis Ready, Cloud Optimized (ARCO) dataset using Xarray and Zarr, from Abernathey et al. 2021.
Zarr has emerged as one of the best ways of storing and sharing ARCO data in cloud object storage. Zarr is a technology for efficient storage and querying of large multidimensional array (a.k.a. tensor) data. Zarr works by splitting large arrays into smaller chunks and storing each chunk as an individual compressed object in object storage, while keeping metadata in lightweight JSON files. Major public agencies such as NASA, ESA and ECMWF have adopted Zarr for internal data analytics use cases (even if they are not yet publishing official Zarr data). Moreover, based on our experience, about 80% of private sector companies working with weather, climate, and geospatial data in the cloud are using Zarr as their core data-cube format. Notable users include Google Research (e.g. WeatherBench2), NVIDIA (Earth-2) and Microsoft (Planetary Computer).
However, as usage has grown, some challenges have emerged around the Xarray / Zarr cloud ecosystem. From talking to hundreds fo Zarr users over the past few years, we’ve identified three core problems that are holding organizations back from from fully embracing ARCO data.
- Consistency - Zarr works well in read-only scenarios, but when update operations fail mid-write, or when multiple clients try to simultaneously read from / write to the same Zarr datasets, consistency issues emerge. At the root of these issues is the fact that a Zarr is not just a single file but rather spans multiple files / objects in physical storage. Seen as an array database management system, Zarr on object storage offers poor ACID guarantees in the context of multiple-reader / multiple-writer scenarios.
- I/O Performance - Despite Zarr’s cloud-native design, the current Python stack doesn’t always deliver the I/O performance that demanding teams expect in terms of latency and throughput.
- Cost of Data Transformation - While some teams are happy to just batch convert their NetCDFs to Zarr, others, particularly on the public-sector side, are required to maintain archival formats for interoperability with existing data systems. These organizations want to have their cake and eat it too—store thousands of NetCDF files but query them as singular ARCO datasets in the cloud-native way. Kerchunk and VirtualiZarr have demonstrated that this is indeed possible, but challenges remain in operationalizing this approach.
We’ve thought deeply about how to solve these problems. In fact, we solved them once already, in our Arraylake Platform! 😆 Now that we’ve had this system in production for over a year, under heavy load from real users, we’ve realized that we can best serve both our customers and the broader scientific data community by evolving our storage model to take advantage of object storage in a deeper way and open-sourcing the core technology.
The Technology
Icechunk was inspired by the rise of “table formats” for columnar data: Apache Iceberg, Delta Lake, Apache Hudi, and Lance. These formats demonstrate how it’s possible to provide database-style operations—ACID transactions, automatic partitioning, optimized scans, etc.—for analytical tables using only object storage as the persistence layer. Furthermore, these formats illustrate how different query engines, from Snowflake to DuckDB, can all interoperate safely and consistently on the same underlying data, without the need for any locks or server-side coordination. These are exactly the sort of capabilities that the scientific data community needs in order to get the most out of the cloud.
But there’s one critical problem with these table formats for our use case: they’re all designed exclusively for tabular data. Scientific data require large multidimensional arrays that simply can’t be represented in the tabular data model.
We didn’t want to create a new format from scratch—we’re excited that Zarr is becoming the de-facto standard in this field! Instead, we wanted to make Zarr work a bit more like a database, while keeping the same core data model and ecosystem that users love. From this goal, Icechunk was born.
Icechunk is a transactional storage engine for Zarr. Let’s break down what that means:
- Zarr is an open source specification for the storage of multidimensional array (a.k.a. tensor) data. Zarr defines the metadata for describing arrays (shape, dtype, etc.) and the way these arrays are chunked, compressed, and converted to raw bytes for storage. Zarr can store its data in any key-value store.
- Storage engine - Icechunk exposes a key-value interface to Zarr and manages all of the actual I/O for getting, setting, and updating both metadata and chunk data in cloud object storage. Zarr libraries don’t have to know exactly how Icechunk works under the hood in order to use it.
- Transactional - The key improvement that Icechunk brings on top of regular Zarr is to provide consistent serializable isolation between transactions. This means that Icechunk data are safe to read and write in parallel from multiple uncoordinated processes. This allows Zarr to be used more like a database.
Beyond the transaction capabilities, Icechunk’s design brings a few big features of broad interest to our community:
- Ability to “time travel” between different snapshots of the dataset, enabling both robust recovery from all kinds of errors (i.e. “undo changes”) as well as sophisticated git-style data version control (tags and branches). And it does this without ballooning the storage volume, by storing only diffs between snapshots.
- Ability to store “chunk references” i.e. Kerchunk-style pointers to chunks in existing NetCDF or HDF files. Icechunk can therefore serve as a production-grade backend storage format for Kerchunk and VirtualiZarr. For users, these datasets are indistinguishable from “regular” Icechunk / Zarr datasets. Furthermore, they can be incrementally updated / overwritten one chunk at a time.
- Numerous performance enhancements and optimization opportunities designed to deliver the best possible I/O performance for analytical and machine-learning workloads.
We decided to implement Icechunk in Rust, with a thin Python layer on top as the interface with Zarr. Rust is an ideal choice for a cloud-native storage library. Its emphasis on correctness helped us rapidly iterate on different designs while maintaining a consistent high-level data model and API. The great performance of Rust’s Tokio async runtime allows us to squeeze every last millisecond of performance out of object storage. And the integration with Python is a breeze. (Don’t worry, you don’t have to know any Rust to use Icechunk! It’s all under the hood.)
In the course of implementing Icechunk, we also had to make some choices about our Zarr dependency: would Icechunk support the legacy Zarr V2 format, or would we lean into the new Zarr V3 format? We opted for pushing forward into the future by making Icechunk require Zarr V3. Along the way we drove a total refactor of the Zarr Python library resulting in a new major version (Zarr Python 3). Zarr Python 3 and Icechunk work hand in hand to deliver major performance enhancements compared to version 2, and even without Icechunk, Zarr users can expect huge benefits, particularly around Zarr’s new async API.
Performance
At this stage of development, we’ve barely begun the process of optimizing Icechunk for performance, focusing first on the core design of the format, algorithms, and the correctness of the implementation. However, good design plus Rust translate immediately into performance benefits.
Below is the result of our initial benchmarking.
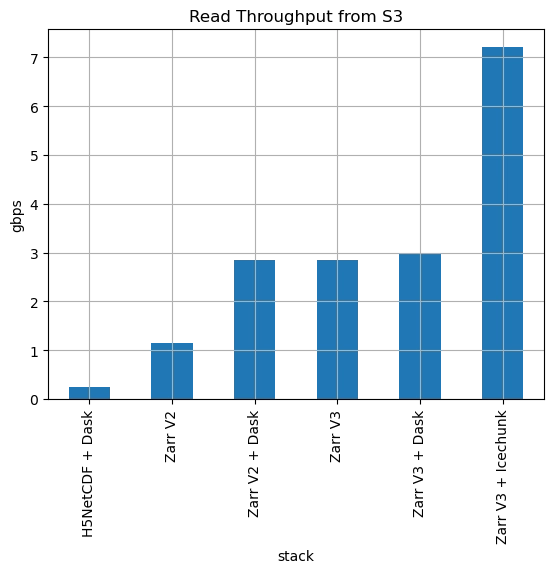
Performance analysis of various I/O stacks for reading data from S3. The NetCDF dataset was a 1.8 GB NetCDF file (4GB uncompressed) from the NSF NCAR Curated ECMWF Reanalysis 5 (ERA5) The dataset was transformed to Zarr with zstd compression and written in both V2, V3, and V3 + Icechunk format. It was read back using Xarray plus different I/O stacks, with and without Dask. More details in Github.
We focused our initial benchmark on read throughput (measured in gbps, higher is better), since this is the quantity most relevant to analytical workloads and ML training pipelines. From this figure, we can draw the following conclusions:
- Reading NetCDF4 / HDF5 data directly from object storage using h5py delivers very poor throughput.
- Zarr V2 already delivers nearly a 10x boost, exceeding 1 gbps.
- Using Dask with V2 increases throughput to nearly 3 gbps. Users of the existing Python stack today know that Dask is required to get the most throughput from Zarr.
- Zarr V3 delivers the same performance out of the box, without Dask, due its new codec threadpool and asyncio Store layer.
- Icechunk delivers more than 2x improvement on top of this, boosting throughput to over 7 gbps. This is quite close to the network capacity of this EC2 instance (10 gbps).
We have not dug into exactly why Icechunk is so fast. It was a pleasant surprise we discovered just a few days ago! Right now, our assumption is that this is the benefit of having all of the network I/O in Rust.
We haven’t done any explicit performance optimization yet, so we’re very excited to push these promising results much further.
Evolution of the Earthmover Platform
Why did we decide to open-source features that were previously paid features of our platform (Arraylake)? The answer is simple: we listened to our customers. Hundreds of conversations with different teams over the past year revealed how much organizations of all sizes value open source, particularly when it comes to the core technology used to store their precious data. Adopting Icechunk as our platform’s storage format ensures that our customers will always have maximum flexibility and freedom with their own data.
The value offered by the Earthmover platform goes way beyond the on-disk format. Arraylake is a full-stack cloud data management platform which liberates scientific data teams from the toil and tech-debt of building their own bespoke data infrastructure from scratch. Our focus is on solving the operational engineering problems that constitute the “undifferentiated heavy lifting” of cloud-native scientific data systems. Here are some of the key features of Arraylake that are not part of the open-source Icechunk library:
- Fine-grained role-based access controls (RBAC) and integration with cloud IAM for controlling who within your org can read and write to Icechunk datasets
- A powerful web-based catalog to browse and explore your data
- Automatic Icechunk garbage collection, chunk compaction, and other optimizations for speed and storage savings
- Full metadata search
- Industry-standard SLA
- Data stored in organization’s own cloud storage buckets
- White glove support from the Earthmover team
- Tight integration with other Earthmover services, including our forthcoming query service and ingestion engine (more on this soon!)
The true magic happens when we pair Icechunk with Arraylake. With the performant foundation of Icechunk, plus the collaboration and data governance features of Arraylake, we think that cloud-native scientific data management is ready to go mainstream! 🚀
Interested in learning more? Book a call with our team today!
The Open Source Community
We’re thrilled about the impact that Icechunk will have on the broader Earth system data community. Our company’s roots are in open source. As a Public Benefit Corporation, the mission of building open-source software to empower scientists is written into our corporate charter. Yet for the past two years, most of what we have built has been proprietary, accessible only to customers able to pay for enterprise software subscriptions.
It’s very satisfying to have found a way to align our business objectives with our open source aspirations. Our team is proud to put something great out into the world that is 100% free and open source. We truly believe that Icechunk will be a game changer for the scientific data community, enabling organizations large and small to work with cloud data in a safe, robust, and high-performance manner.
Getting Started with Icechunk
The core entity in Icechunk is a repository or repo. A repo is defined as a Zarr hierarchy containing one or more Arrays and Groups, and a repo functions as a self-contained Zarr Store. The most common scenario is for an Icechunk repo to contain a single Zarr group with multiple arrays, each corresponding to different physical variables but sharing common spatiotemporal coordinates.
To create your first Icechunk repo, just pip install icechunk and head over to icechunk.io to get started
What’s next?
We’re super excited about the Icechunk release. At the same time, we’re just at the beginning of the journey. We’ve got big plans for Icechunk, and there is a lot of work ahead
We can’t wait to get your feedback on Icechunk. We welcome your issues and pull requests on GitHub.
If you’re interested in learning more or chatting with the Icechunk developers, please join the Earthmover Slack.
We’ve also got some big new platform features in the pipeline! Stay tuned for another big announcement soon, and don’t forget to sign up for our mailing list to receive updates from Earthmover.
CEO & Co-founder