
Blog
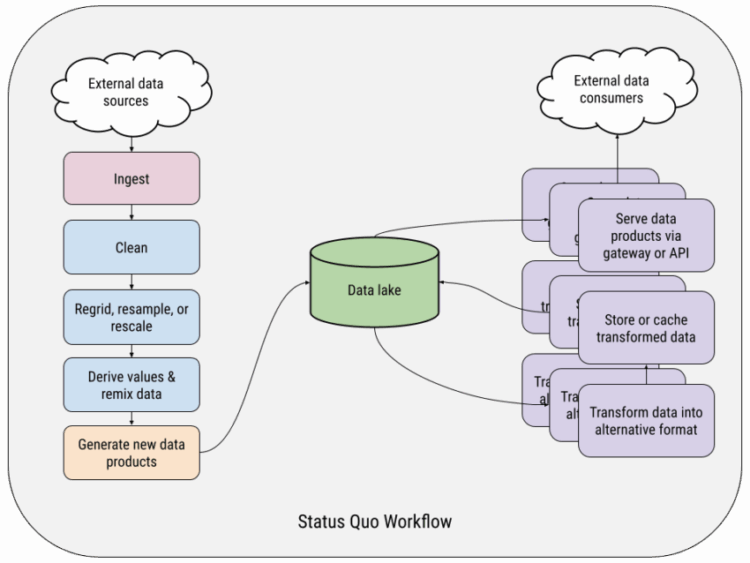
TensorOps: Scientific Data Doesn’t Have to Hurt
Okay friends, it’s time to take the Data Pain Survey: If your answer to any of the preceding questions was...
Read more
Brian Davis

Zarr takes Cloud-Native Geospatial by storm
Our takeaways from the Cloud-Native Geospatial conference on Zarr’s surging adoption and its impact on the future of Earth Observation...
Read more
Joe Hamman
Co-founder and CTO

Meet the Earthmover Team at the Cloud Native Geospatial Conference 2025!
The Earthmover team is heading to Snowbird, Utah for the Cloud Native Geospatial (CNG) Conference 2025 this week. For our...
Read more
Joe Hamman
Co-founder and CTO
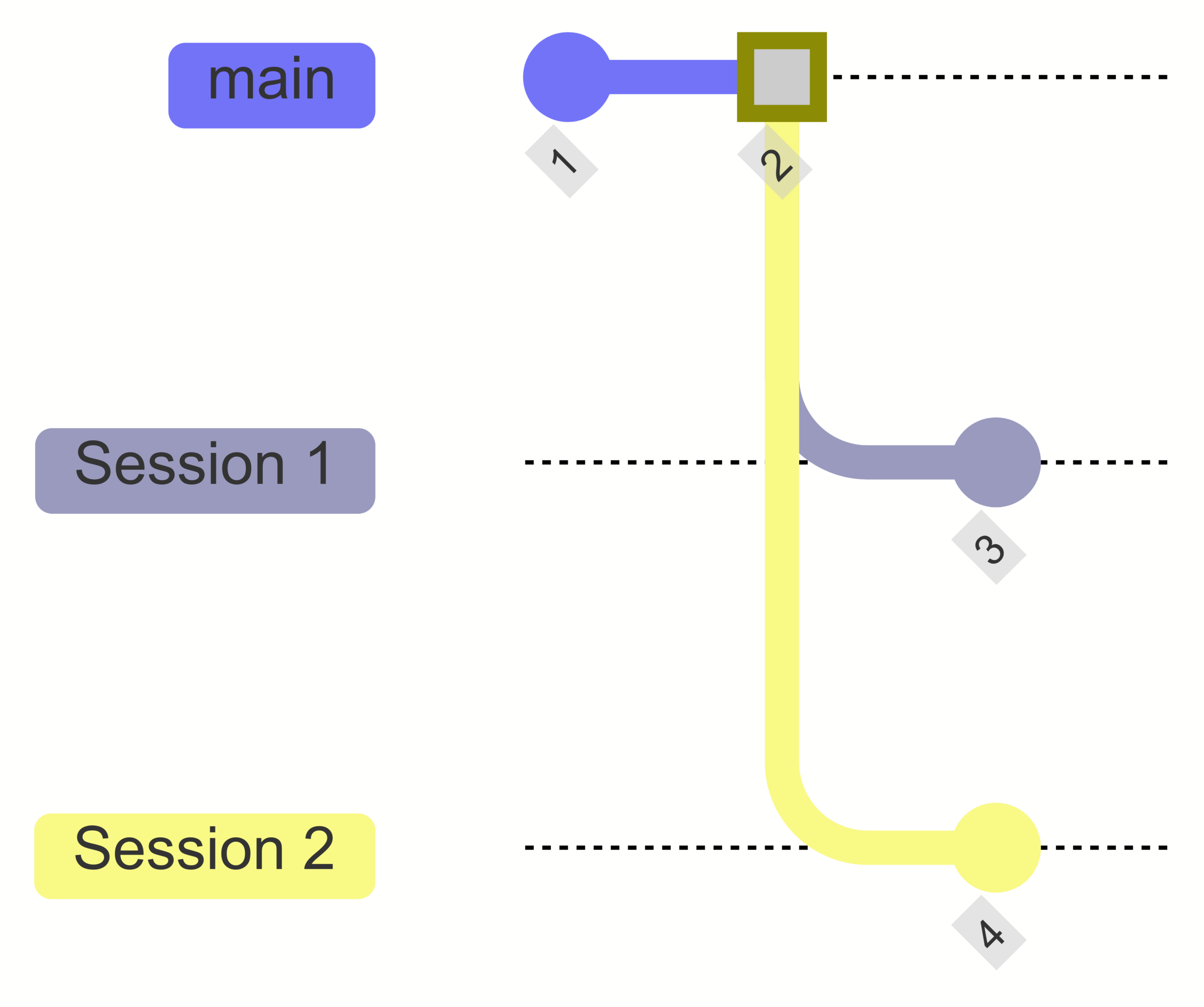
Learning about Icechunk consistency with a clichéd but instructive example
In this post we’ll show what can happen when more than one process write to the same Icechunk repository concurrently,...
Read more
Sebastian Galkin
Staff Engineer
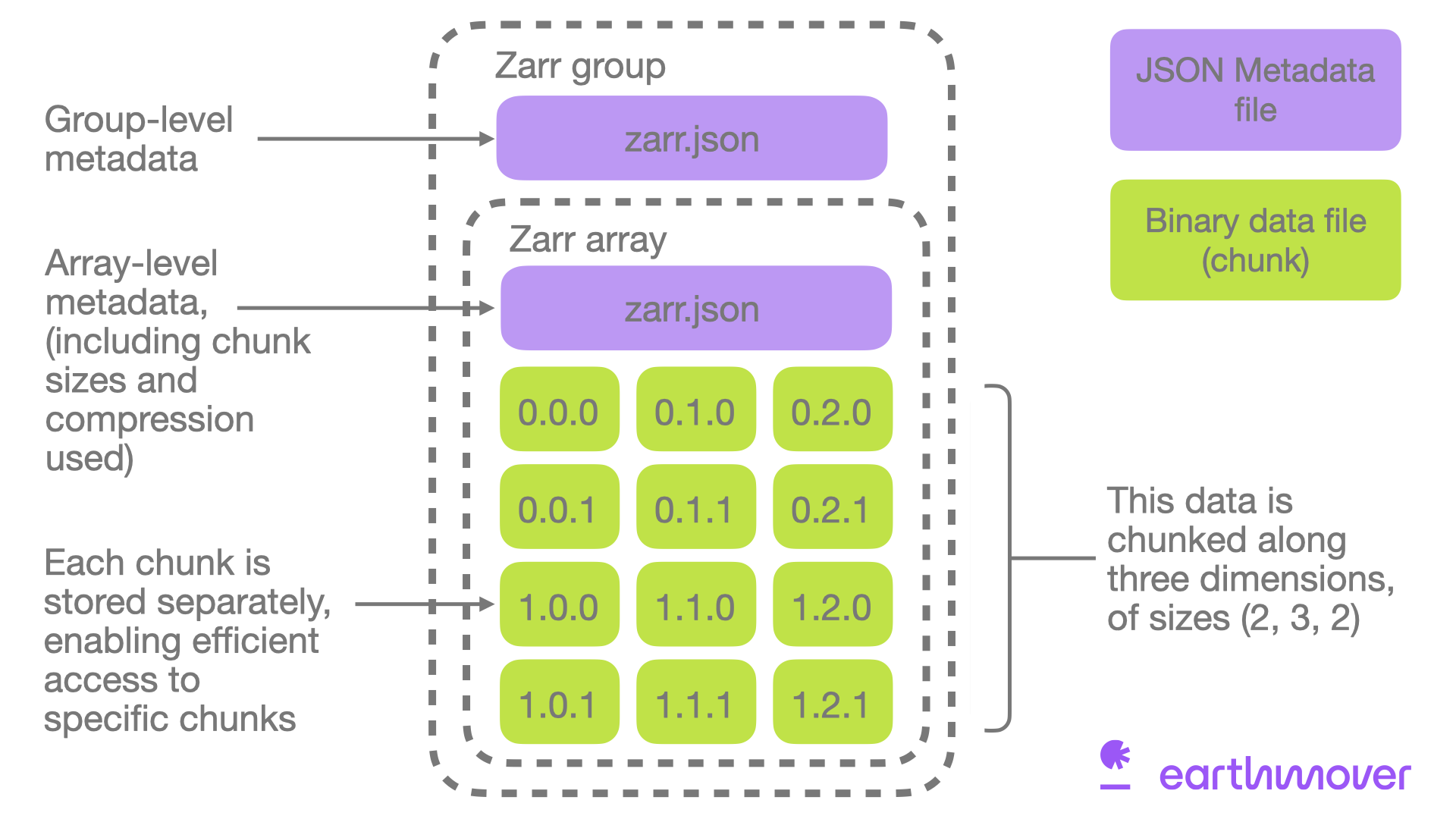
Fundamentals: What is Cloud-Optimized Scientific Data?
Why naively lifting scientific data to the cloud falls flat. Scientific formats predate the cloud There are exabytes of scientific...
Read more
Tom Nicholas
Forward Engineer

Announcing Flux: The API Layer for Geospatial Data Delivery
TLDR Earthmover’s new product–Flux–adds a whole new layer to our platform. Flux allows you to serve geospatial data from Arraylake...
Read more
Ryan Abernathey
Co-Founder and CEO

Exploring Icechunk scalability: untangling S3’s prefix story
We at Earthmover recently released the Icechunk tensor storage engine, a novel cloud-optimized storage format and library for large-scale array data. Built...
Read more
Sebastian Galkin
Staff Engineer
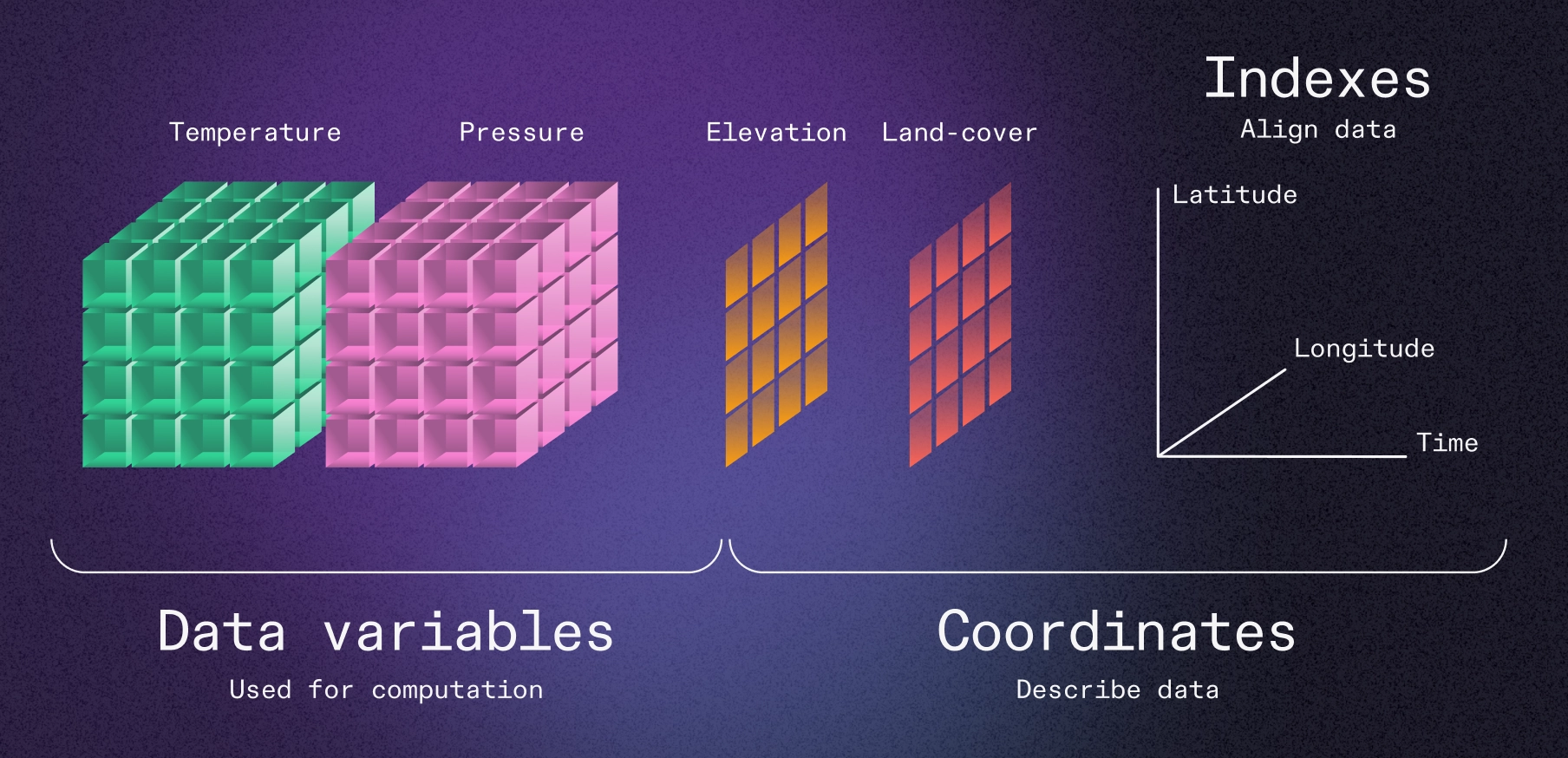
Fundamentals: Tensors vs. Tables
At Earthmover, we are building the cloud platform for multidimensional array data (a.k.a. tensors). While the need for such a...
Read more
Ryan Abernathey
Co-Founder and CEO