Fundamentals: What Is Zarr? A Cloud-Native Format for Tensor Data


Software Engineer
Why scientists, data engineers, and developers are turning to Zarr
Often the biggest bottleneck in your workflow isn’t your code or your hardware, but the way your data is stored. Data formats can limit–or unlock–what you’re able to do with your data. In modern science and data-intensive computing, they influence everything from performance to scalability to collaboration.
Whether you’re working with climate models, satellite imagery, or massive machine learning datasets, the structure behind your data can determine the limits of your work. Traditional formats like NetCDF, HDF5, and TIFF have long served the research community well, but as data grows bigger and more distributed, new tools are needed.
Enter Zarr: a simple but powerful open-source, cloud-native protocol for storing chunked, compressed N-dimensional arrays. Designed for performance, interoperability, and the cloud, Zarr is quietly transforming the way researchers and developers handle large datasets. In this post, we’ll walk through the fundamentals of Zarr—what it is, how it works, and why it’s gaining traction across industries.
What is Zarr?
“Zarr is like Parquet for arrays”
Zarr is an open-source protocol for storing multi-dimensional-array datasets, like measurements over time, space, or other variables, as N-dimensional arrays. Think of it as a lightweight, modular alternative to older formats like HDF5, designed to work especially well with cloud storage and large-scale computing.
You can also think about Zarr as “Parquet for array data.” Parquet is a columnar storage format optimized for tabular data (like what you’d find in dataframes or relational databases), while Zarr is a chunked storage protocol optimized for multi-dimensional array data. Zarr plays a similar role for n-dimensional arrays as Parquet does for tabular data—both are efficient, compressed, and designed for analytics and scalable access patterns, especially in cloud and distributed environments.

Zarr is specifically designed for tensor data: multi-dimensional arrays that generalize scalars (0D), vectors (1D), and matrices (2D) to higher dimensions, commonly used to represent complex structured data in machine learning and scientific computing. If you are curious why we prefer to build array-native data systems rather than converting data to a tabular format, check out this blog post.
At its core, the Zarr specification stores data in chunks—small, manageable pieces of large arrays that can be read and written independently. Each chunk is compressed to save space, and the entire dataset is organized in a hierarchical directory-like structure with simple JSON metadata files. This makes Zarr both human-readable and highly portable.
Zarr is designed to be:
👉 Flexible: Works across local file systems, cloud object stores like Amazon S3 or Google Cloud Storage, and distributed file systems.
👉 Efficient: Enables fast, parallel I/O—ideal for distributed computing with tools like Dask, Ray, Spark, or Beam.
👉 Self-describing: Metadata is embedded directly alongside the data, so each array carries information about itself, like dimensions, data types, or custom attributes, without needing external documentation.
👉 Open and Multi-stakeholder: With an open spec, growing ecosystem, and community governance, Zarr is not tied to any single vendor or platform.
If you’re working with large arrays and want fast access, compression, and compatibility with the cloud, Zarr is worth a look.
How is data stored in Zarr?
The Zarr data specification organizes data as a hierarchical structure that mirrors the shape and organization of your arrays. Here’s a quick breakdown of how the data is stored (based on the Zarr V3 storage specification):
Data Organization
Zarr separates where data is stored from how it’s organized, using two key concepts: stores and groups.
A Store is the backend that defines where the data physically lives. A Zarr store can be:
- A directory on disk (e.g., LocalStore)
- A cloud bucket (e.g., FsspecStore for s3://…)
- An in-memory dictionary (e.g., MemoryStore)
- A custom system like Icechunk (covered below)
A Group is a logical container for organizing data, like folders in a file system.
- A group can contain multiple related Zarr arrays
- It can also hold other groups (nested hierarchy)
- Each group has its own metadata (in zarr.json)
- Groups live within a store
Chunks
Zarr stores array data in chunks—uniform, fixed-size blocks that break large arrays into manageable pieces. Each chunk is saved as a separate binary file inside a c/ directory and is organized using nested folder paths based on its index (e.g., c/0/0/0 for the chunk at position [0, 0, 0]).
This chunked layout is key to Zarr’s performance: it enables fast, scalable access by allowing applications to load only the chunks they need, rather than the entire dataset. Whether you’re analyzing a small slice of a multi-terabyte array or streaming data from cloud storage, chunking makes large-scale, distributed workflows efficient and practical.
Metadata
Zarr uses structured metadata to describe not just individual arrays, but the full hierarchy of a dataset. This metadata is stored in zarr.json files throughout the directory tree:
- Array-level metadata: Each array directory contains a zarr.json file that describes the array’s shape, data type, chunking scheme, and compression options.
- Group-level metadata: Every group has its own zarr.json, which stores attributes and metadata relevant to that group.
- Store-level metadata: At the root of the store, a top-level zarr.json file defines global configuration and identifies the dataset as using the Zarr v3 spec.
Because metadata is embedded at every level of the hierarchy, Zarr datasets are self-describing and navigable. You can traverse a dataset from the root down to nested arrays, reading metadata along the way, just like navigating directories in a file system. This hierarchical metadata model also enables lazy loading, where metadata can be read and explored without loading the full dataset into memory—ideal for working with massive or remote datasets.
The file structure for a Zarr dataset stored on disk might look something like this:
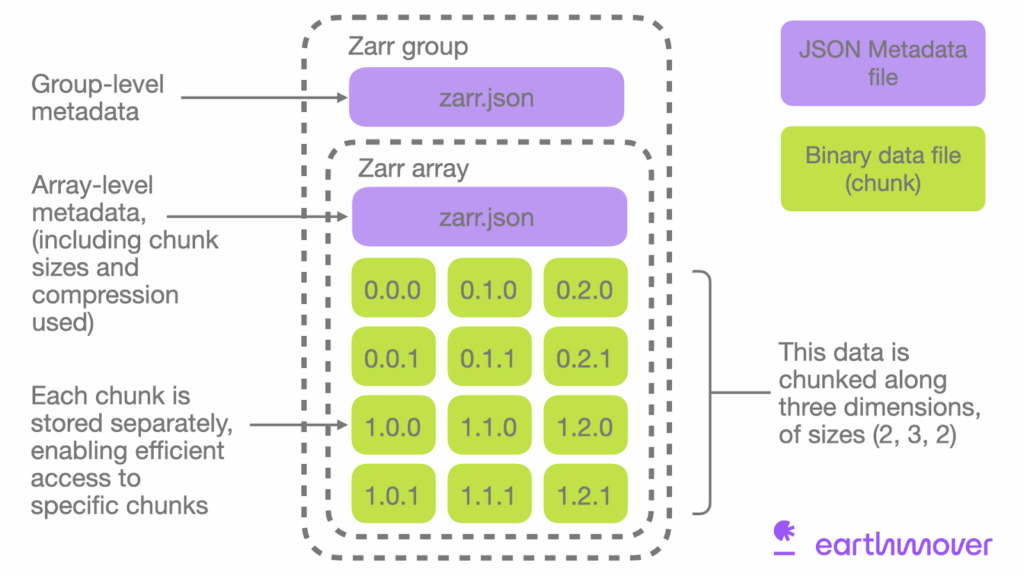
Diagram of the structure of a Zarr v3 store, showing how the metadata is separated into dedicated files, and the data is split into chunks.
This structure scales to cloud environments, where each chunk can be a separate object in S3 or GCS. Because Zarr relies on simple file operations, it also avoids locking issues that can arise with single-file formats like HDF5.
What makes Zarr “cloud-native”?
Zarr is considered a cloud-native data format because it is designed to work seamlessly with cloud storage systems and to take advantage of cloud computing capabilities. To understand what makes data “cloud-optimized”, check out our blog post on the topic!
Here are the key reasons why Zarr is cloud-native:
🧱 Chunked Storage for Efficient Access
Zarr stores data in chunks (small, fixed-size blocks) rather than in large monolithic files. This allows for:
👉 Selective Data Loading: Only the chunks needed for a specific task are loaded into memory, making it possible to work with very large datasets without having to load the entire dataset.
👉 Parallel Access: Multiple chunks can be read or written concurrently, which is well-suited for distributed cloud environments where parallelism is a key feature.
☁️ Cloud-Optimized Layout
Zarr is designed to work efficiently with cloud storage systems (e.g., Amazon S3, Google Cloud Storage, Azure Blob Storage). It supports:
👉 Distributed Storage: Zarr stores can be hosted on scalable, cloud-based object storage systems—enabling parallel access, remote availability, and efficient handling of large datasets across distributed computing environments.
👉 Consolidated Metadata: Zarr’s consolidated metadata feature packs all structural metadata into a single file, dramatically reducing the number of costly network calls needed to explore or load datasets stored in remote object stores.
⚙️ Cloud-Based Parallel Computing
Zarr integrates well with distributed computing frameworks like Dask, Spark, Ray, or Beam, which enables cloud-native parallel processing. This allows:
👉 Out-of-Core Computation: Data that doesn’t fit into memory can be processed in chunks, and computations can be distributed across multiple cloud nodes, making it ideal for cloud-based workflows.
👉 Scaling: Zarr datasets can scale effortlessly in cloud environments, handling very large volumes of data by leveraging the cloud’s storage and compute capabilities.
🔓 Open and Flexible Access
Zarr’s use of standard, cloud-friendly protocols means it can be accessed via common tools like:
👉 S3-compatible APIs: Zarr works directly with cloud storage services via APIs, enabling easy access to large datasets stored in the cloud.
👉 RESTful Access: Zarr data can be stored in formats compatible with cloud object storage systems (such as S3), which typically use REST APIs for interaction, enabling ease of access and sharing across cloud-based services.
Zarr is cloud-native because it is designed to efficiently handle distributed data storage, support scalable cloud computing workflows, and seamlessly integrate with modern cloud platforms and tools. Its chunked storage system, combined with cloud-optimized access patterns and compatibility with compute tools, makes it an ideal protocol for working with massive datasets in the cloud.
What does the Zarr Python API look like?
If you’re familiar with NumPy, you’ll feel right at home with Zarr. The core Python API provides a similar array-based interface, with added control over how your data is stored and accessed. Although the official Zarr implementation is written in Python, the protocol is supported by multiple languages, including Java, C++, Rust, and R, enabling broad interoperability across diverse computing environments.
Here’s a quick example of creating and writing to a Zarr array using the Python API:
This example illustrates Zarr support for reading and writing to arbitrary slices, even when they span multiple chunks. You don’t need to manage or even be aware of the underlying chunking scheme—Zarr takes care of that behind the scenes, so you can work with the array just like you would with NumPy
As outlined above, you can use Zarr groups to organize data hierarchically, similar to folders or HDF5 groups:
Most users don’t need to use this interface directly; instead, they use higher-level tools that talk to Zarr for them.
What tools make up the Zarr ecosystem?
Zarr isn’t just a data protocol—it’s the foundation for a growing ecosystem of tools that make it easier to read, write, analyze, and visualize large datasets. No matter your field, whether it’s climate science, finance, or machine learning, there are tools ready to work with your Zarr data.
🧩 Xarray
Xarray provides a high-level, labeled array interface that works seamlessly with Zarr, making it an ideal tool for working with large, multidimensional datasets. Xarray enhances raw Zarr arrays by adding coordinate labels, metadata, and powerful slicing capabilities—perfect for scientific data like weather, climate, or satellite observations.
With Xarray, you can transform raw numerical data into richly structured datasets that are easy to manipulate and analyze:
In this example, Xarray transforms a simple Numpy array into a labeled dataset with time, latitude, and longitude coordinates. It then writes the dataset to Zarr and reads it back into Xarray’s data representation format.
Lazy loading comes into play when Xarray loads the Zarr data. Instead of reading the entire dataset into memory, Xarray only loads the metadata and a small portion of the data as needed, allowing you to efficiently work with large datasets without overloading memory. This makes it ideal for analyzing large-scale scientific datasets that may not fit in memory all at once.
Zarr vs. Xarray: What’s the Difference?
Zarr is a protocol for storing large, chunked arrays on disk or in the cloud. Xarray, on the other hand, is a Python library for working with labeled multi-dimensional arrays. While Zarr handles how data is stored, Xarray focuses on how data is accessed, analyzed, and manipulated in memory. Xarray can read and write Zarr datasets, but it is not a data storage format itself.
Xarray makes it easy to work with large, complex datasets stored in Zarr, offering an intuitive interface for handling scientific data that requires clear labeling and efficient access. Zarr is about storage efficiency; Xarray is about analytical power.
🧊 Icechunk
Icechunk builds on Zarr to bring transactional consistency and data integrity guarantees–features typically found in database systems. It is especially useful for teams where safe concurrent writes and data consistency are crucial, such as in production environments for live cloud-based data systems. Icechunk extends Zarr’s capabilities by offering a versioned data model and support for ACID (Atomicity, Consistency, Isolation, Durability) transactions. See this blog post for a real-world example of how Icechunk consistency works.
Here’s a code example of how Icechunk works alongside Xarray and Zarr:
In this example, the Icechunk repository is set up to use S3 as the storage backend. We create a writable session on a specific branch of the repository, allowing us to commit changes incrementally, similar to version control in Git. This ensures that all operations on the data, like writing or updating arrays, are transactional—changes are only committed when explicitly requested, preserving consistency even in concurrent environments. Read about how Icechunk stores these data “snapshots” here.
Icechunk was also built as a cloud-native data format for high-concurrency tasks over large datasets. Learn more about its scalability in the full blog post here.
The combination of Icechunk and Zarr allows for safe concurrent writes, versioned data, and rollback support, which is particularly important in applications involving shared storage environments. Icechunk’s integration with Zarr provides a way to work with large datasets in a distributed, collaborative manner, ensuring both data integrity and efficient, parallel access.
⚙️ Dask
Dask brings parallelism and scalability to Zarr. It breaks Zarr datasets into many small tasks that can run across multiple cores or nodes, enabling out-of-core computation on massive arrays:
Together, Dask and Zarr power many cloud-scale data workflows, making it possible to process large datasets efficiently without loading everything into memory. Other compute tools that integrate well with Zarr are Ray: a general-purpose distributed computing framework that can scale Python applications from a laptop to a cluster and Coiled: a service built around Dask, making it easier to run Dask + Zarr workflows in the cloud with autoscaling clusters.
🔗 VirtualiZarr
VirtualiZarr offers a Zarr-native way to work with existing data formats like NetCDF or HDF5 by accessing data in those formats via the Zarr store API. This enables efficient access and analysis without converting or duplicating the original files—ideal for streaming or migrating legacy datasets in cloud-based workflows.
🧬 OME-Zarr
OME-Zarr is a bioimaging-specific implementation of Zarr, developed as part of the OME-NGFF (Next-Generation File Formats) initiative. It provides a standardized, cloud-ready way to store large, complex microscopy datasets, including multiscale pyramids, multi-channel images, and rich metadata. Backed by community-driven specifications, OME-Zarr is supported by a growing ecosystem of tools like napari, MoBIE, and Bio-Formats, enabling scalable visualization, analysis, and sharing of bioimaging data.
🌏 Pangeo
Unlike the above tools, Pangeo is not a library, it is a community and ecosystem built around tools like Xarray, Dask, and Zarr for big data geoscience. Pangeo provides scalable, cloud-ready infrastructure for analyzing massive datasets, especially in climate science, oceanography, and remote sensing.
Who uses Zarr?
Zarr’s design makes it attractive across a wide range of fields where large datasets, parallelism, and cloud workflows are common. Some notable adopters include:
🌍 Climate and Earth Sciences
Widely adopted by organizations like NASA, NOAA, ECMWF, and the Pangeo community, Zarr is used to store satellite observations, climate model outputs, and remote sensing data. It powers cloud-optimized versions of massive datasets such as CMIP6 and Copernicus products—including Sentinel data, which the Copernicus Earth Observation Processing Framework (EOPF) will make available in Zarr later in 2025. See here for more details.
🔬 Bioimaging and Life Sciences
OME-Zarr is an emerging standard for storing multi-resolution microscopy and 3D imaging data, replacing bulky TIFF stacks with efficient, cloud-ready pyramids that support fast, scalable access. Adopted by leading institutions such as EMBL and the Chan Zuckerberg Initiative, OME-Zarr is unlocking new possibilities for visualization, analysis, and data sharing in life sciences.
🧬 Genomics
Zarr is used to store large-scale sequencing datasets, including reference genome alignments and high-dimensional gene expression matrices. Its chunked, compressed structure supports efficient access and analysis across massive genomic datasets. Projects like scverse (for single-cell omics), zarr-matrix (for sparse gene expression data), and BioGenies (for genomic variant data in the cloud) are adopting Zarr to scale interactive analysis and streamline access to petabyte-scale resources.
🤖 Machine Learning
Zarr enables efficient streaming of training data in large-scale machine learning pipelines. It integrates seamlessly with tools like Dask and PyTorch, supporting out-of-core processing and cloud-native model training.
Who could benefit from Zarr (and Icechunk)?
While Zarr is already powering tools across science, climate, and AI research, its true potential lies in unlocking cloud-native access to high-resolution, multi-dimensional array data—transforming what’s possible in industries that depend on Earth system information. Paired with Icechunk, which brings transactional consistency and scalable compute integration to Zarr, entirely new classes of real-time, intelligent data applications become feasible.
At Earthmover, we are seeing adoption across sectors as diverse as weather, insurance, commodities trading, conservation, energy forecasting, power grid management, and wildfire risk. We are also excited about the use of Zarr in applications like flood risk mapping, defense intelligence, and transportation ops. If you have tensor data and need fast, scalable, and reliable access in the cloud, Zarr and Icechunk may be the foundation your next-generation geospatial applications are built on.
Zarr and Icechunk are powering real-time, cloud-native geospatial analytics.
When should you use Zarr?
Zarr isn’t always the perfect solution, but it shines in certain scenarios. Here’s a practical guide to when you should consider using Zarr, and when another format might be a better fit. Stay tuned for upcoming posts where we’ll dive deeper into Zarr applications across industries and use cases!
✅ Use Zarr if…
👉 **You’re working with very large N-dimensional arrays
** Zarr is built to handle arrays that don’t fit in memory—think terabyte-scale climate models, 3D images from microscopes, or genomics matrices.
👉 You need fast, chunked access Whether you’re doing time-series analysis or slicing spatial tiles, Zarr’s chunking gives you fine-grained, efficient access to just the data you need.
👉 You’re operating in the cloud Zarr works naturally with object storage (like S3 or GCS), without requiring any special I/O libraries or downloads. This makes it a great choice for cloud-native workflows and data lakes.
👉 You’re using parallel or distributed computing Zarr is designed for concurrency. Tools like Dask can read and write from multiple chunks at once, speeding up computation on large datasets.
👉 You want an open, inspectable storage protocol Zarr’s JSON-based metadata makes it easy to debug, inspect, and share, without needing special software.
👉 Your dataops are slowed by downloading or updating entire files Zarr’s cloud-native chunking and compression means your data query workloads can efficiently extract or update only the specific data values relevant to the query.
👉 You’re collaborating on shared data and need reliable transactions Vanilla Zarr doesn’t guarantee atomic writes across multiple chunks, meaning simultaneous updates can lead to conflicts or corruption. Icechunk adds transactional guarantees, making it safe for collaborative environments where multiple users or processes are reading and writing data at the same time.
🚫 Zarr might not be ideal if…
👉 You need compatibility with legacy software If you’re in an ecosystem where HDF5 or NetCDF are required (e.g., older Fortran/C codebases), Zarr might not be supported without extra tooling like VirtualiZarr.
👉 You have many tiny arrays instead of a few large ones Zarr shines with large arrays. If you’re storing lots of small arrays, the file overhead might become burdensome, especially on file systems with limits on the total number of files (such as HPC), or those with performance penalties on many small reads.
👉 You prefer single-file formats Zarr stores each chunk as a separate file, which is great for parallel access, but can be less convenient when copying data or archiving.
Why Zarr?
Zarr is quietly driving a shift in how we approach scientific and big data storage. With a focus on simplicity, scalability, and openness, Zarr offers a modern toolset for working with massive datasets, especially in cloud-first and parallel computing environments. It’s not a one-size-fits-all solution, but if you’re hitting the limits of traditional formats—slow I/O, brittle files, or painful scaling—Zarr could be exactly what you need.
But Zarr isn’t just a storage specification. It’s quickly becoming a shared language for data across industries. From Earth observation to bioimaging to machine learning, Zarr enables more interoperable, future-proof workflows. In fact, the European Space Agency is moving the entire Sentinel satellite archive to Zarr, a clear signal that the future of planetary-scale data is chunked, cloud-optimized, and open.
As the ecosystem grows and adoption accelerates, now is the time to get familiar. The future of data isn’t just bigger—it’s smarter, faster, and built on Zarr.
If you’re ready to dive in, explore the official Zarr documentation, install it via pip install zarr, or discover real-world examples in the Pangeo and OME-Zarr communities.
Once you’re underway and actively building data products on top of Zarr, Earthmover enhances your workflows with a suite of management capabilities, including data catalogs, governance controls, scalable cloud infrastructure, and streamlined data distribution. To learn more, visit https://earthmover.io/.
Software Engineer





