Accelerating Xarray with Zarr-Python 3


Software Engineer (Freelance)
zarr-python’s performance paradox
Last month, we released Zarr-Python 3.0 - a ground-up rewrite of the library (read more about it in this post). Beyond the exciting new features in Zarr V3, we put a lot of work into addressing some long standing performance issues with Zarr-Python 2. With the improvements described in this blog post, we’ve achieved a 14x speedup in loading the ARCO ERA5 dataset!
Zarr-Python 2 had a paradoxical performance quirk; although the library could generate massive petabyte-scale datasets, it struggled to perform well when managing large or highly nested hierarchies. For example, listing the contents of a large Zarr group could be painfully slow, particularly if that Zarr group was stored on a high latency storage backend. Zarr users would experience this as long waits when trying to open a Zarr dataset with Xarray.
To take a real example, the ARCO ERA5 dataset is a Zarr group that contains 277 arrays (273 data variables, and 4 coordinate variables). Just collecting the metadata of these arrays takes over a minute with Zarr-Python 2.18, but finishes in under 15 seconds with Zarr-Python 3.
To completely load the data into xarray I can ran the followig code:
In a Google Colab notebook, it completes in about 60 seconds. But at home in Germany, where I have much higher latency, the same code can take nearly 200 seconds!
how to open an xarray dataset
Before we explain why this was so slow, let’s walk through what opening a dataset like ERA5 means in terms of storage operations. Fundamentally, it’s a sequence with two steps:
- List the names of the potential Zarr arrays contained in that ERA5 Zarr group. This takes several seconds, and requires multiple calls to GCS, because GCS returns results in separate pages. The result is a list of 277 names, and each of these is a potential data variable or coordinate variable.
- For each name we got in step 1, we retrieve the following objects:
<uri>/<name>/.zarray, a JSON document which indicates that<name>is in fact a Zarr array<uri>/<name>/.zattrs, a JSON document which contains the metadata Xarray needs to interpret<name>as a data variable or a coordinate variable. If<name>is a coordinate variable, we need to fetch one or more chunk files to get the actual values for that variable.
So open_dataset does 2 steps: getting a list of names, then fetching a bunch of small files for each of those names. The listing step takes less than 10 seconds (try it on Colab), so the remaining 50 - 190 seconds are spent waiting for the “fetch several hundred small files” step to finish. None of the files we need are very large, so why was a big data library like Zarr-Python struggling here?
The problem lies in the heart of the storage API used by Zarr-Python 2. Zarr-Python 2 iterates serially over the list of group names, processing a name only after the previous name was finished. If for any reason GCS is slow to respond to one of our requests, then Zarr-Python simply waits. The time spent waiting scales with the product of the number of names and wait time for each name. If processing a single name takes 0.1 - 0.3 seconds, then processing hundreds of names could take minutes, which is what we observe.
a new storage layer in zarr-python 3
Cloud storage systems like Google’s GCS can handle large volumes of concurrent requests, so why doesn’t Zarr-Python simply leverage this functionality? As Zarr developers, we asked this question many times, but the basic design of the storage layer in Zarr-Python 2 was a blocker. To fix this problem we would need to completely rewrite storage in Zarr-Python, and this would require breaking changes to the library.
But with the release of version 3 of the Zarr storage format, we finally had space to make breaking changes to Zarr Python. So we rebuilt the storage layer from the ground up! This is not a new problem, and there are plenty of established designs we could look to for inspiration. We decided to use asyncio to model I/O operations as lazy functions that can be submitted asynchronously to an executor. This design allows Zarr-Python to submit requests for data and continue doing useful work while those I/O tasks make progress in the background.
Zarr-Python 2 would issue a request for data, wait for it to finish, and only then send the next request; by contrast, Zarr-Python 3 will submit requests concurrently, which means it can submit many tasks at once and process the results as soon as they are ready. In theory this design is much faster at fetching large numbers of files from high-latency storage providers. But the best way to demonstrate how it works in practice is to run some benchmarks, so that’s what comes next!
benchmarking our new storage layer
We measured the time required to invoke xarray.open_dataset on the ERA5 dataset with the latest version of Xarray, across varying Zarr-Python configurations. You can see that we tested Zarr-Python 3 multiple times, with a varying concurrency limit. The concurrency limit is the maximum number of I/O tasks that Zarr-Python will run at once. This is a new feature of Zarr-Python 3, and we made it user-configurable via our new runtime configuration system.
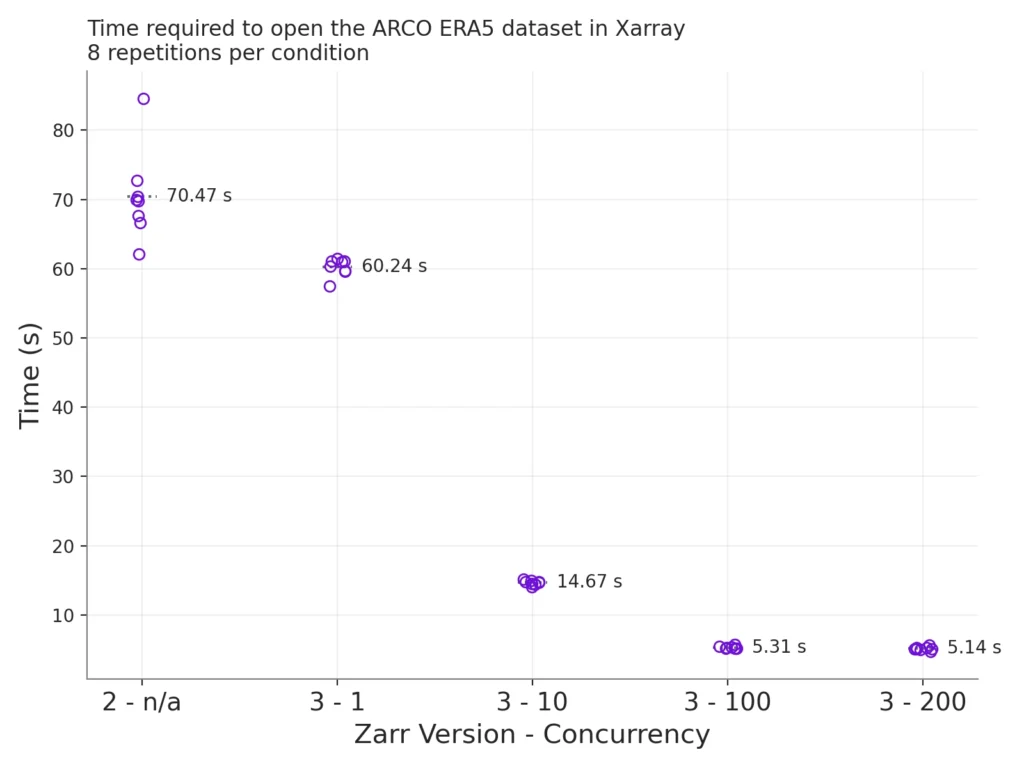
A few takeaways from these results:
- Zarr Python 3 is much faster than Zarr Python 2.
- Even with a concurrency limit of 1 (i.e., no concurrency), Zarr-Python 3 is still faster than Zarr-Python 2. This is likely due to general performance improvements across the Zarr-Python 3 codebase.
- We get big gains when we use more concurrency — we save 10 seconds by setting the concurrency limit from 10 (the default in Zarr-Python today) to 100.
- Returns beyond concurrency of 100 are marginal, at least in this benchmark. Although the default concurrency value is not the topic of this blog post, these results suggest that a default of 10 is a bit low.
what about consolidated metadata?
Zarr and Xarray users have long been aware that listing large Zarr groups can be slow. See for example this discussion in the Pangeo-Data GitHub project. In 2018 Martin Durant added a new feature to Zarr-Python called “consolidated metadata” (zarr-python#268), which gave Zarr-Python the ability to create a special metadata document in a Zarr group that aggregates all of the metadata documents of all the Zarr groups and arrays descended from that root group. This is a very clever re-framing of the “slow listing problem”: instead of reading one metadata document per Zarr group / array, we read just one consolidated metadata document for the entire hierarchy.
Redefining the problem this way completely sidesteps the lack of concurrency in Zarr-Python, but not for free. Metadata consolidation is a non-standard extension to the Zarr format, and not all Zarr implementations support it. As consolidated metadata is effectively the cached result of listing the contents of a Zarr group, changing the state of a Zarr group (like adding a new array or group) after creating consolidated metadata makes that metadata invalid. In other words, consolidated metadata introduces some tricky consistency issues when updating any part of a hierarchy.
Consolidated metadata isn’t going anywhere, and we fully support it in Zarr-Python 3. But with these new performance gains, perhaps we don’t need consolidated metadata as much. If so, we anticipate that fewer datasets will need metadata consolidation to provide a good user experience, which is a win from a simplicity standpoint. And for truly enormous Zarr groups that still need metadata consolidation, these I/O performance improvements in Zarr-Python 3 will also make the process of building that consolidated metadata document faster than ever.
what’s next
We made major progress toward resolving a longstanding performance problem in Zarr-Python 2, but we still have a lot more work to do. This post focused on the performance of a single function in Xarray, but we are working to improve performance a multiple points of Xarray / Zarr interaction:
- Zarr loader optimizations: We added an optimization in Xarray’s Zarr loader that greatly reduces the number of I/O operations needed when listing Zarr arrays xarray#9861. For a dataset like ERA5, this change shaves an additional 1 second off the time required to run
open_dataset. - Faster dataset creation: We are developing a new API in Zarr-Python for concurrently creating many Zarr groups and arrays with a single function call zarr-python#2665. Once this effort is complete, Xarray can use this functionality to speed up
Dataset.to_zarr. If the benchmarks in this post are any indication, we should expect at least an order of magnitude speedup. - Batched array reading and writing: The concurrent storage API in Zarr-Python 3 can in principle read and write many separate Zarr array values concurrently, but we have not developed user-facing functions for this in Zarr-Python yet. Once we do, we expect even more performance improvements for dataset access.
- Icechunk: Icechunk solves the same problem as consolidated metadata, but does so without introducing consistency issues. Preliminary benchmarks using Icechunk with Xarray and Zarr-Python 3 show even more substantial performance gains when working with complex hierarchies.
We want to keep up this rapid pace of improvement, so if you use Xarray with Zarr and there’s something you’d like changed or fixed, please open an issue in the Zarr-Python issue tracker!
credits
The overall Zarr-Python 3 refactor was a community effort with more than 30 contributors 🎉. The changes to Xarray and Zarr were done in xarray#9861 and zarr-python#2519 were done by Davis Bennett with support from Earthmover and the Chan Zuckerberg Foundation.
Software Engineer (Freelance)






